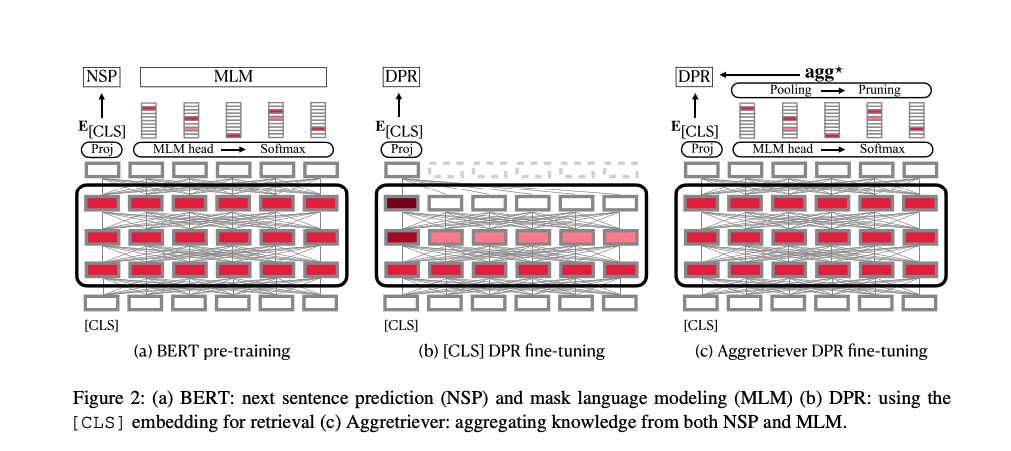
Aggretriever: A Simple Approach to Aggregate Textual Representations for Robust Dense Passage Retrieval - TACL2023
Motivation: Recent work has shown that models such as BERT are not ‘‘structurally ready’’ to aggregate textual information into a [CLS] vector for dense passage retrieval (DPR). This ‘‘lack of readiness’’ results from the gap between language model pre-training and DPR fine-tuning. Methods: In this work, we instead propose to fully exploit knowledge in a pretrained language model for DPR by aggregating the contextualized token embeddings into a dense vector, which we call agg*. Experiments: By concatenating vectors from the [CLS] token and agg*, our agg* retriever model substantially improves the effectiveness of dense retrieval models on both in-domain and zero-shot evaluations without introducing substantial training overhead.
2024.02.26
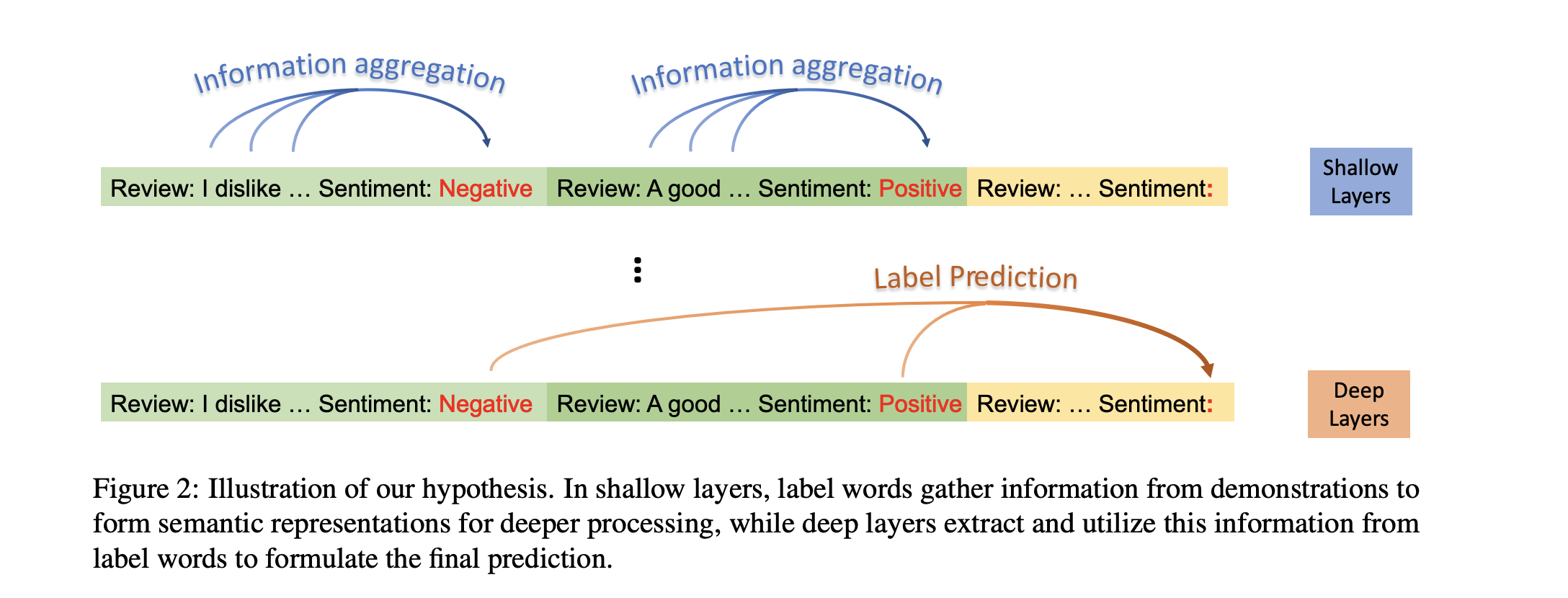
Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning - EMNLP2023 Best Paper
Investigate the mechanisms of ICL. Click Learn more for more details.
2023.01.16
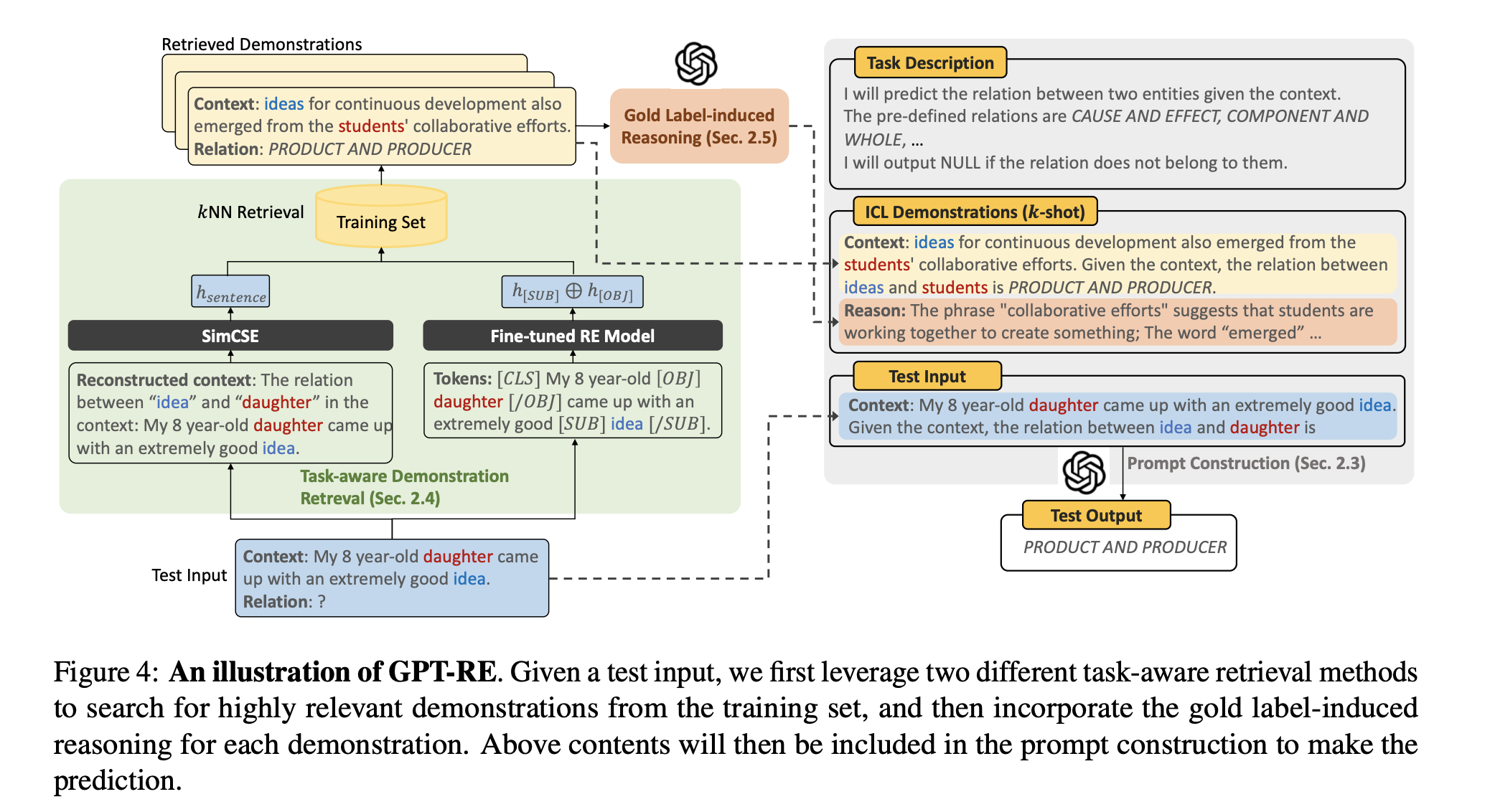
GPT-RE: In-context Learning for Relation Extraction using Large Language Models
Existing In-context Learning with LLMs still lag behind fully supervised baselines due to two major shortcomings of ICL: (1) low relevance regarding entity and relation in existing sentence-level demonstration retrieval approaches for ICL; and (2) the lack of explaining input-label mappings of demonstrations leading to poor ICL effectiveness. This paper proposed two task-level representations methods for demonstration retieval and enrich each demonstration with gold label induced reasoning logic. Despite of the effectiveness, this method still needs to query LLMs (GPT-3) in this paper, which may bring more consumption of time and money. The demonstration-level reasonging logic is novel and it brings gains for the relation extraction. Datasets: Semeval, TACRED, SciERC, and ACE05.
2023.01.15

Expected Calibration Error (ECE) of LLMs
Click "learn more" to read the blog.
2023.01.12
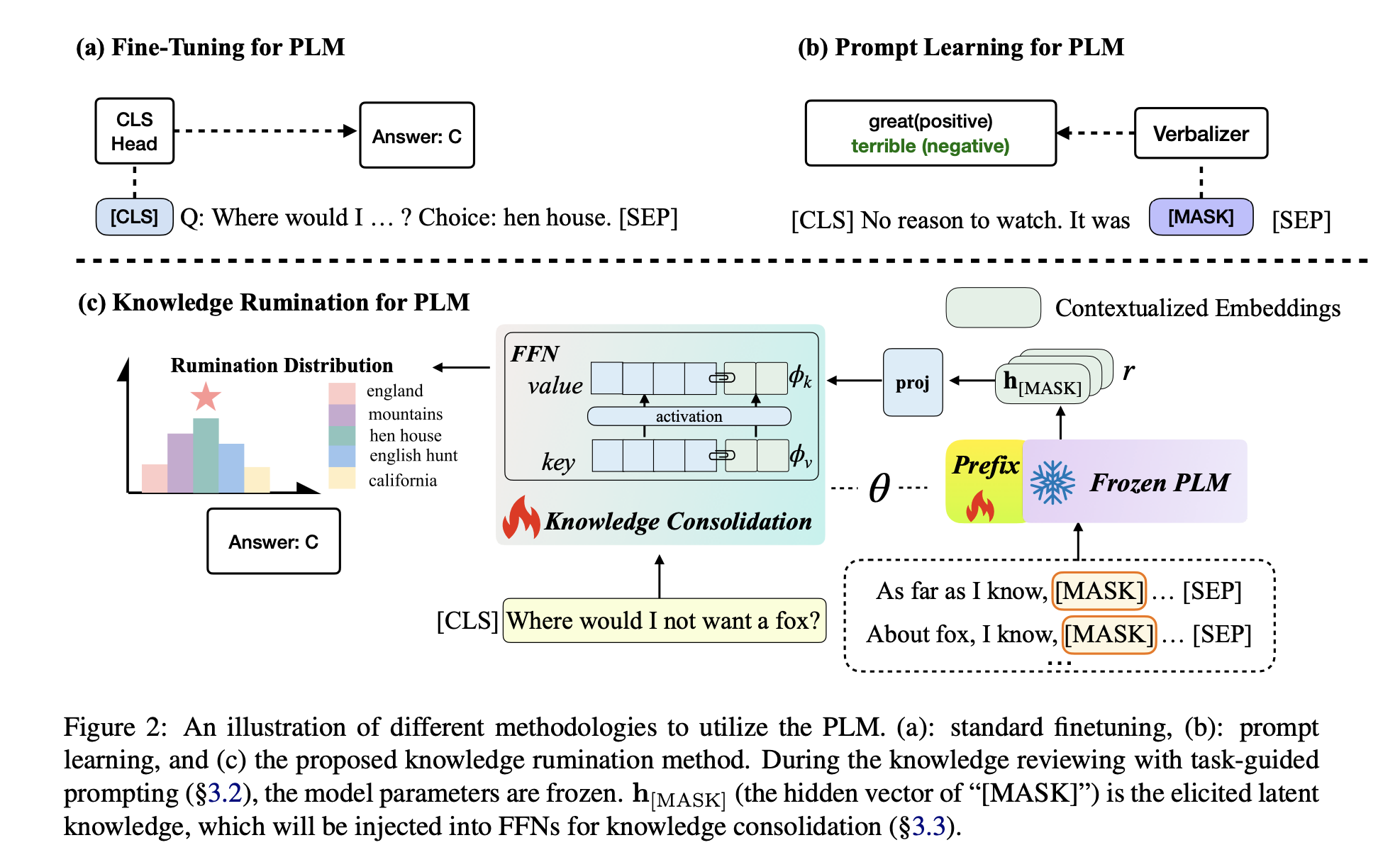
Paper reading "Knowledge Rumination for Pre-trained Language Models" -- ACL2023
This paper observes that pre-trained language models (PLMs) encode rich knowledge for certain knowledge-intensive tasks but struggle to effectively utilize this encoded information. In response, a method called knowledge rumination is proposed to aid PLMs in leveraging latent knowledge without the need for retrieval from an external store. Specifically, the approach involves freezing the PLMs and designing multiple-level prompts to obtain embeddings that encode task-related information. These embeddings are then incorporated into the top-1 layer of the trainable PLMs by integrating them into Feedforward Neural Networks (FFNs), as FFNs have been identified as the knowledge or skill neurons. Extensive experiments conducted on CommonsenseQA (CSQA), SocialIQA, PhysicalQA (PIQA), Openbook QA (OBQA), HellaSwag, and Abductive Natural Language Inference (aNLI) demonstrate the effectiveness of the proposed method.
2023.01.06
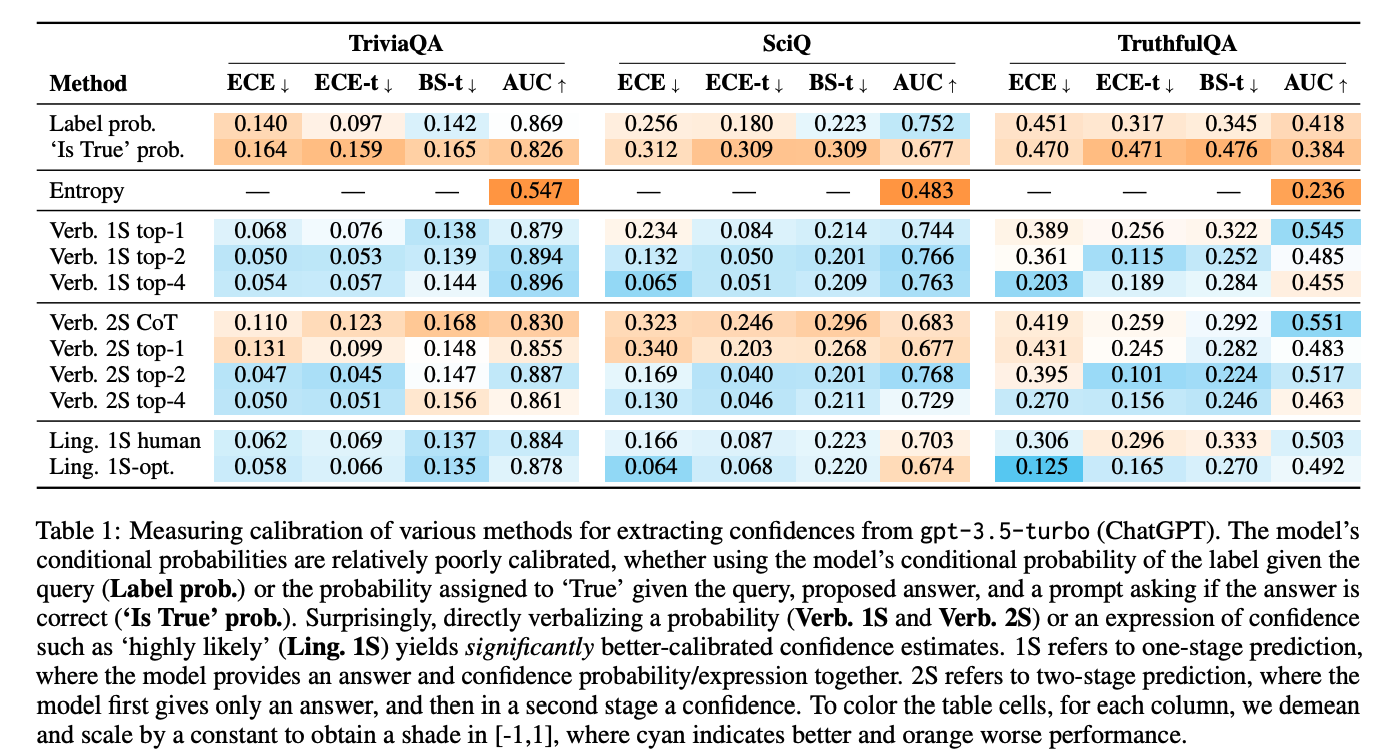
Paper reading "Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback" -- EMNLP2023 shot paper
Existing widely used language models (LMs) are fine-tuned using reinforcement learning from human feedback (RLHF LMs), and some studies have demonstrated that RLHF LMs generate poorly calibrated conditional probabilities. Certain findings suggest that RLHF-LMs may prioritize adherence to user instructions in dialogue over well-calibrated predictions (Kadavath et al., 2022; OpenAI, 2023). This is because the reinforcement learning objective encourages the model to assign probability mass to the most preferred answer(s) rather than aligning with the relative frequency of possible answers. This paper conducts extensive experiments to assess methods for extracting confidence scores from RLHF-LMs. The results indicate that verbalized confidence emitted as output tokens is typically better calibrated than the model's conditional probability.
2023.01.11

Paper reading "Data Curation Alone Can Stabilize In-context Learning" -- ACL2023
This paper demonstrates that meticulous curation of a smaller training dataset from a larger pool can significantly enhance the stability of Incremental Classifier Learning (ICL). A training subset is defined as stable if randomly sampling a sequence of examples from it results in significantly higher average and worst-case accuracy compared to random sampling from the original sets. The paper introduces two methods to score all training examples and select those with the highest scores to compose the final stable subset. The CondACC method calculates the expected accuracy conditioned on an example's score, akin to the Data Shapley value. The Datamodel method involves training a data model (a linear regressor) to predict the outcome of a training example from an LLM's outcome. Examples with outcomes greater than 0 are considered good examples. Experimental results on five classification tasks validate the effectiveness of the proposed methods. The study conducts a comprehensive analysis on various dimensions, including sequence length, perplexity, and diversity, rendering the insights gained from the analysis meaningful.
2023.01.05
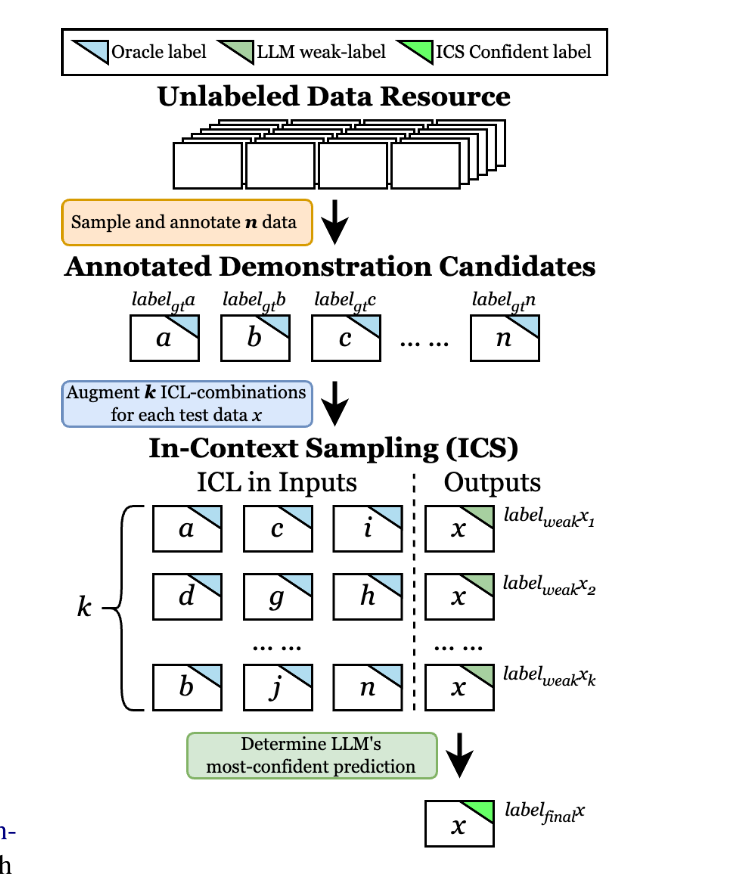
Paper reading "More Samples or More Prompt Inputs? Exploring Effective In-Context Sampling for LLM Few-Shot Prompt Engineering" -- Arxiv2023
This paper is more likely to be an idea instead of a paper. This paper proposed an In-context Sampling (ICS) method, which first samples some demonstration candidates and then constructs different conbinations of demonstrations. The proposed method aims to select representative demonstrations and maximize the diversity. The statement "Dmonstrations could provide LLM with ..." could be referred in wiriting.
2023.01.04
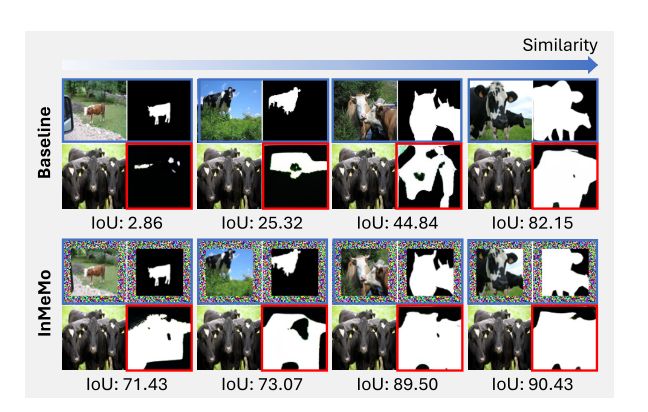
Paper reading "Instruct Me More ! Random Prompting for Visual In-Context Learning -- WACV2023
This paper explored in-context learning in computer vision and introduce a method coined Instruct Me More (InMeMo), which augments in-context pairs with a learnable perturbation.
2023.01.03
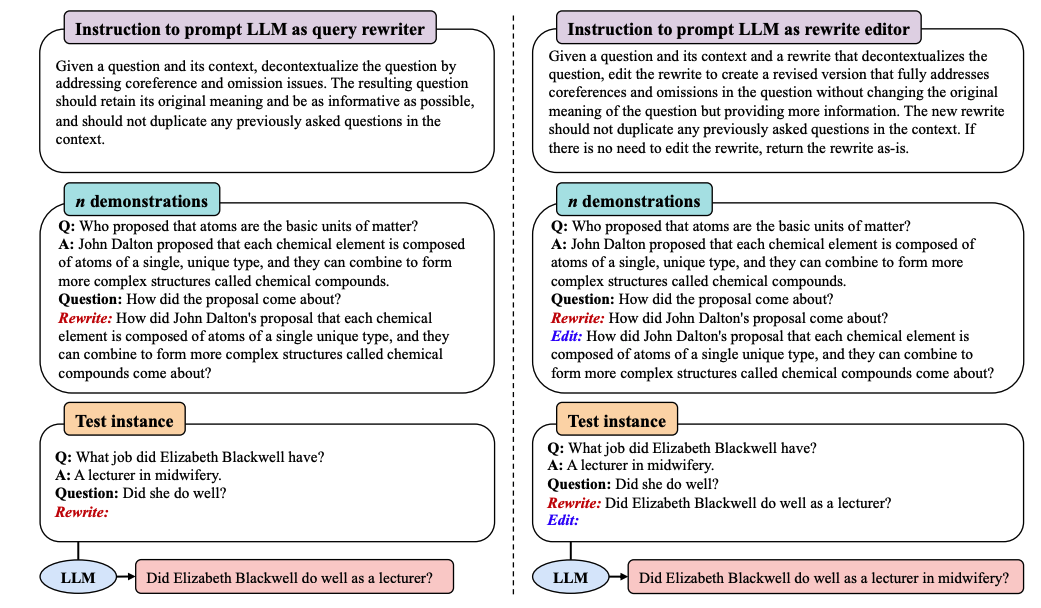
Paper reading "Enhancing Conversational Search: Large Language Model-Aided Informative Query Rewriting" -- EMNLP2023 Findings
Existing query rewriting methods train models relying on human rewrited labels, which lack sufficient information for optimal retrieval performance in conversational search. This paper proposed to use LLM as query rewriter, and designed four propoties, namely correctness, clarity, informativeness, and nonredundancy. The method used quey, answer, rewrite query, and initial query to construct demonstrations in few-shot learning. Furthermore, they proposed distilling the rewriting capabilities of LLMs into smaller models to reduce rewriting latency. This paper gave some expressions why distill the capability of LLM to small LM, such as the reliance on third-party API services and high cost. Experimental evaluation on the QReCC dataset demonstrates that informative query rewrites can yield substantially improved retrieval performance compared to human rewrites, especially with sparse retrievers.
2023.12.25
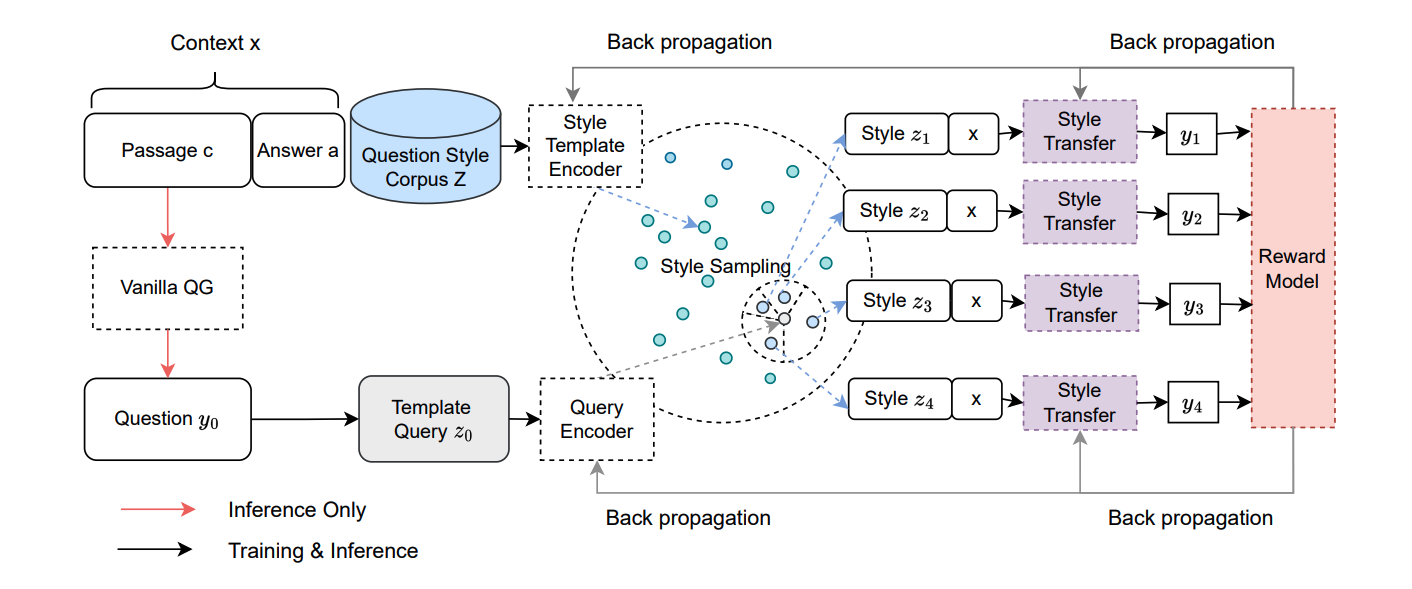
Paper reading "Diversify Question Generation with Retrieval-Augmented Style Transfer" -- EMNLP2023
This paper aims to solve the question generation task and improve the diversity of the generated questions. However, existing methods exploiting knowledge from external storage ignore the diverse expressions in the external data. This paper proposed a method, namely RAST, to retrieve question templates and transfer question styles. To train the framework, this paper also proposed different rewards based on LLM and used RL to update the parameters of the template retrieval model and the generation model. The RL method and style transfer method give me some insights.
2023.12.25
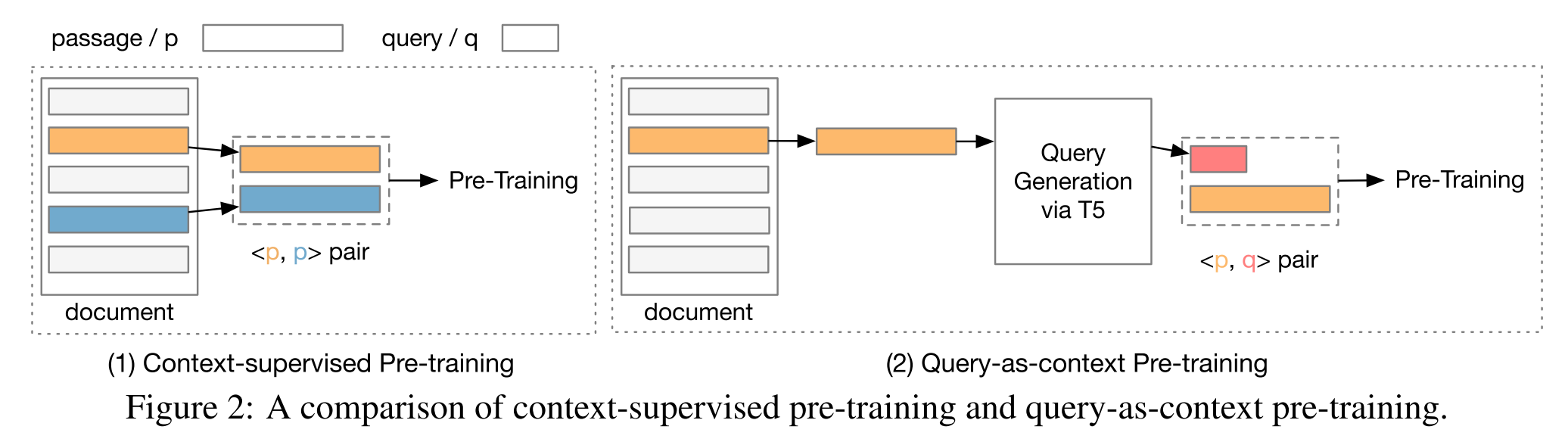
Paper reading "Query-as-context Pre-training for Dense Passage Retrieval" -- EMNLP2023
The training process of for dense retrieval aim to imporove the text representation modeling ability of the encoder through auxiliary self-supervised or context supervised tasks. However, existing context supervised methods ignore the irrelavcence of between the passages within the same document, which do not align with the assumptions on which cannot align with the assumptions on which context-supervised pre-training is based, and are likely to be detrimental to context-supervised pre-training. Thus, this paper focuses on exploring query prediction techniques to im- prove context-supervised pre-training methods for dense retrieval. This method used a off-the-shell query prediction model to generation candiate queries and pre-train two retrievers on them. Two popular MLMs methods are combined with the proposed methods to prove the effectiveness on passage retrieval tasks.
2023.11.30
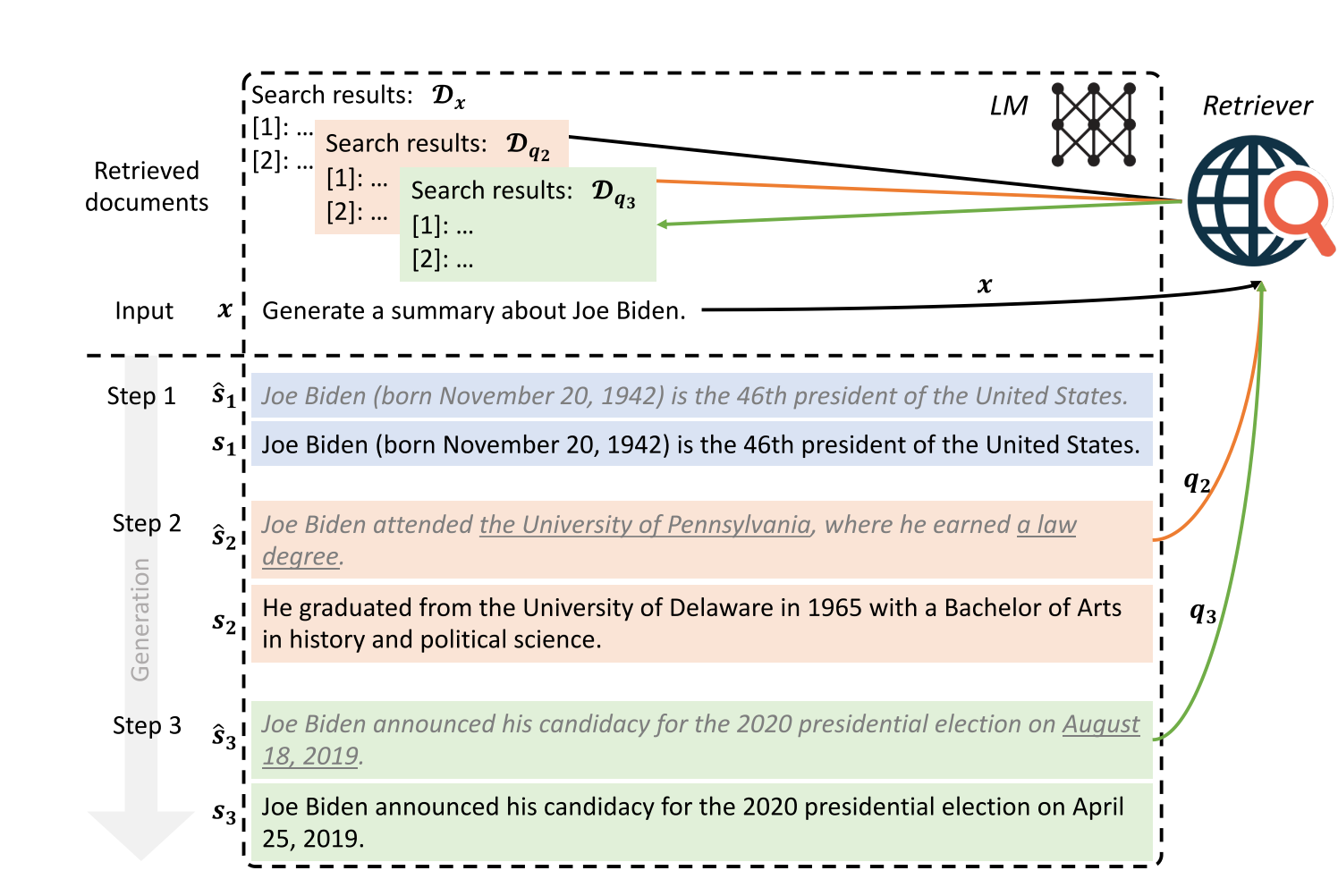
Paper reading "Active Retrieval Augmented Generation" -- EMNLP2023
This paper proposed a Forward-Looking Active REtrieval augmented generation method, which conducts multiple retrieval during text generation. This method could resolve the long-form generation better, where the context information are not evident from the input text. It decides when and what to retrieve. Notably, this paper refers two meaningful and worthy observations: (1) LLMs tend to be well-calibrated and low probability/confidence often indicates a lack of knowledge; (2) Since the black-box LLMs cann't be fine-tuned, so the generation from them might not be reliable. The two observations could give me some inspirations.
2023.11.29
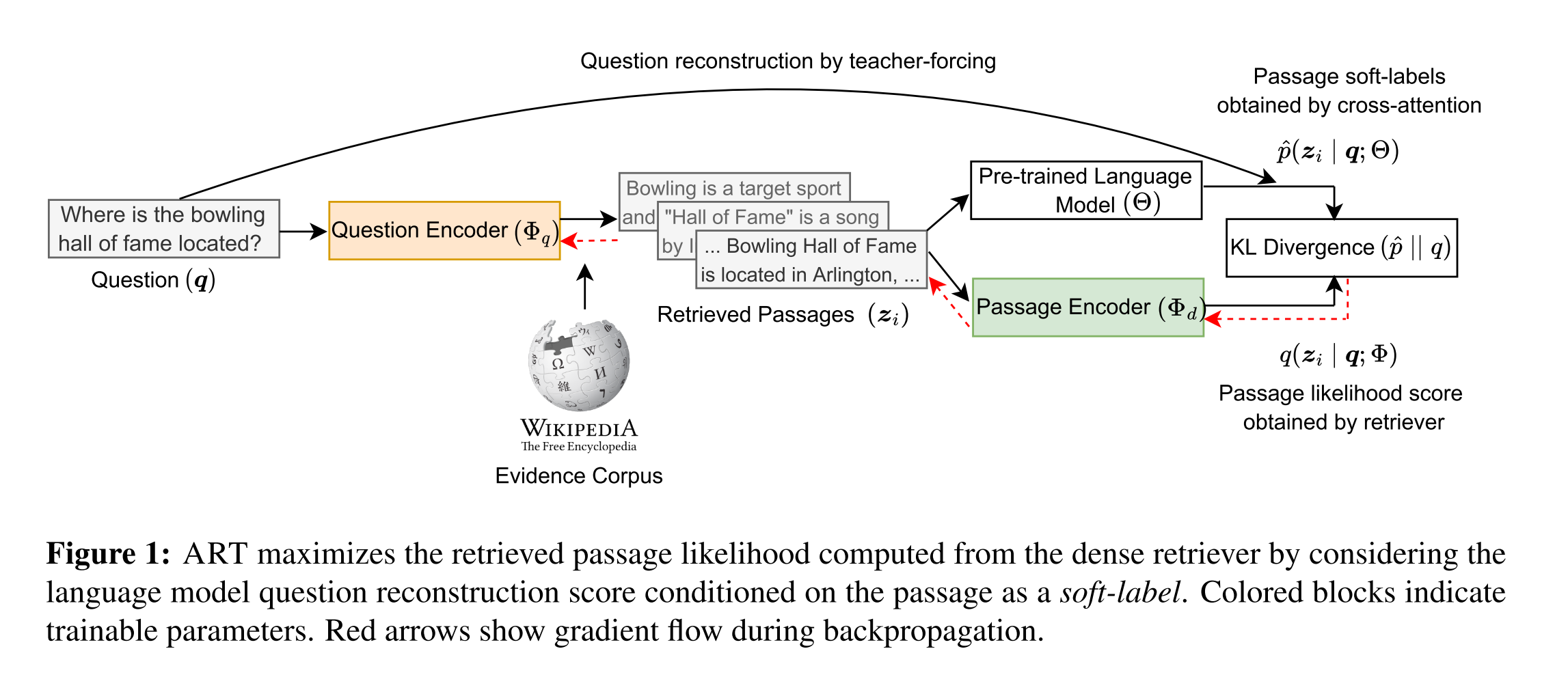
Paper reading "Questions Are All You Need to Train a Dense Passage Retriever" -- TACL2023
This paper proposed an Autoencoding-based Retriever Training (ART), which is an unsupervised method to train the retriever. ART first retrieved several possible candidate passages as evidence then reconstructing the original question by attending to the retrieved passages. The main idea is to consider the retrieved passages as a noisy representation of the original question and question reconstruction probability as a way of denoising that provides soft-labels for how likely each passage is to have been the correct result. Actually, the reconstruction is realised by aligning the retrieval scores and PLM relevance score estimation. The former scores serve as a student distribution while the latter serve as a teacher distribution. Experiments are conducted on different QA datasets to improve the effectiveness and robustness of ART and the influence of hyper-parameters.
2023.11.27

Paper reading "SOUL: Towards Sentiment and Opinion Understanding of Language" -- EMNLP2023-main
The emergence of LLMs leads to a common belief that sentiment classification has reached its saturation. This paper proposed a new dataset named Sentiment and Opinion Un- derstanding of Language (SOUL) to evaluate sentiment understanding through two subtasks: Review Comprehension (RC) and Justification Generation (JG). Each data contains a text review, a statement, a label indicating the truthfulness of the statement, and a justification. Experiments compared the performance different pre-trained language models and large language models across the SOUL dataset. Maybe the main contribution of this paper sits at the new dataset.
2023.11.27
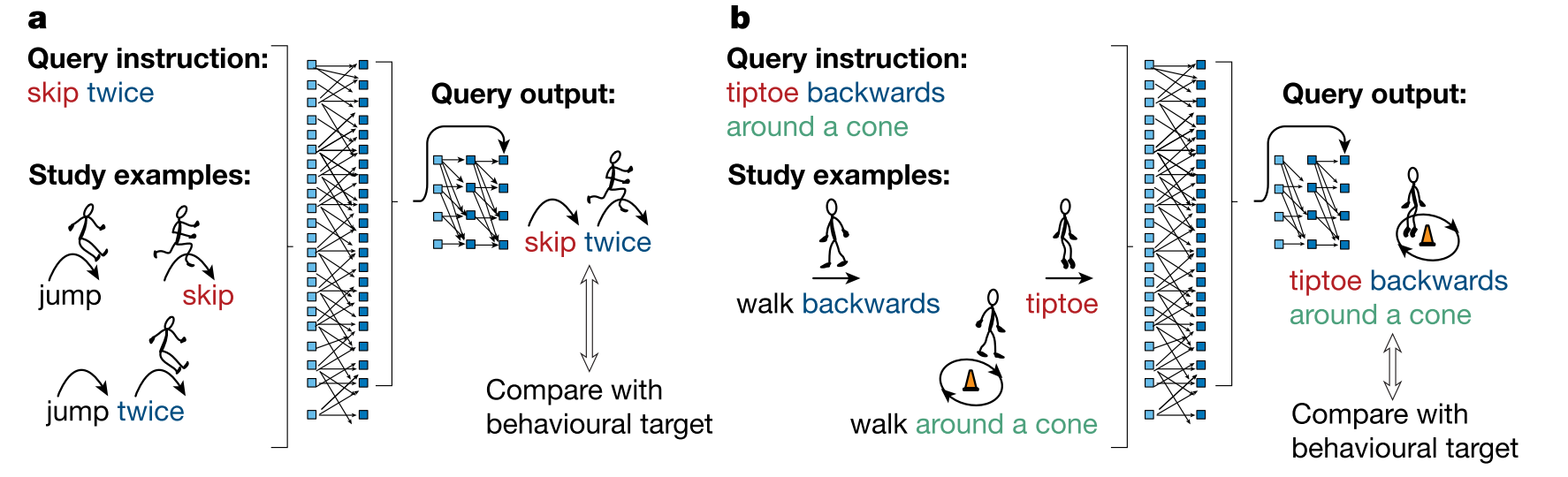
Paper reading "Human-like systematic generalization through a meta-learning neural network" -- Nature2023
This paper provdides evidence that neural networks can achieve human-like systematicity when optimized for their compositional skills and introduces the meta-learning for compositionality (MLC) approach for guiding training through a dynamic stream of compositional tasks. Comparison results to human experiments demonstrated that only MLC achieves both the systematicity and fexibility needed for human-like generalization. MLC also advances the compositional skills of machine learning systems in several systematic generalization benchmarks.
2023.11.11
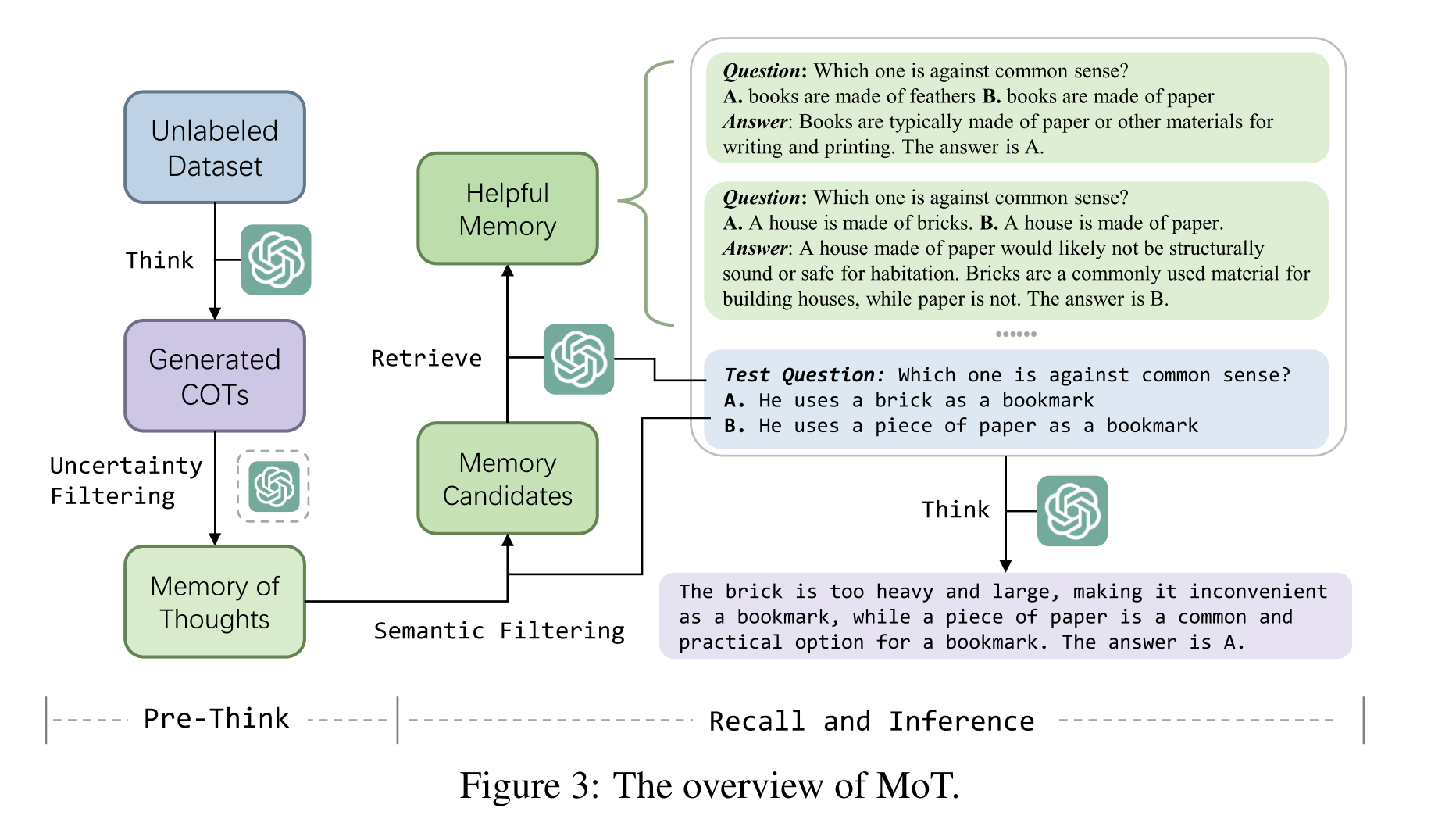
Paper reading "MoT: Memory-of-Thought Enables ChatGPT to Self-Improve" -- EMNLP2023 main
(1) Motivation: Existing studies collecting high-quality annotated datasets and fine-tuning the LLM is costly and may decrease its general ability. Humans can improve their own reasoning abilities through the metacognition process and the memory mechanisms, preserve their general abilities. (2) Methods: We propose Memory of Thought(MoT) to let LLM think on the unlabeled dataset and save the thoughts in the pre-thinking stage and recall relevant memory in the test stage. (3) Experiments: Extensive experiments show that MoT can help ChatGPT improve its abilities in arithmetic reasoning, commonsense reasoning, factual reasoning and natural language inference without parameter updates and annotated datasets.
2023.11.10
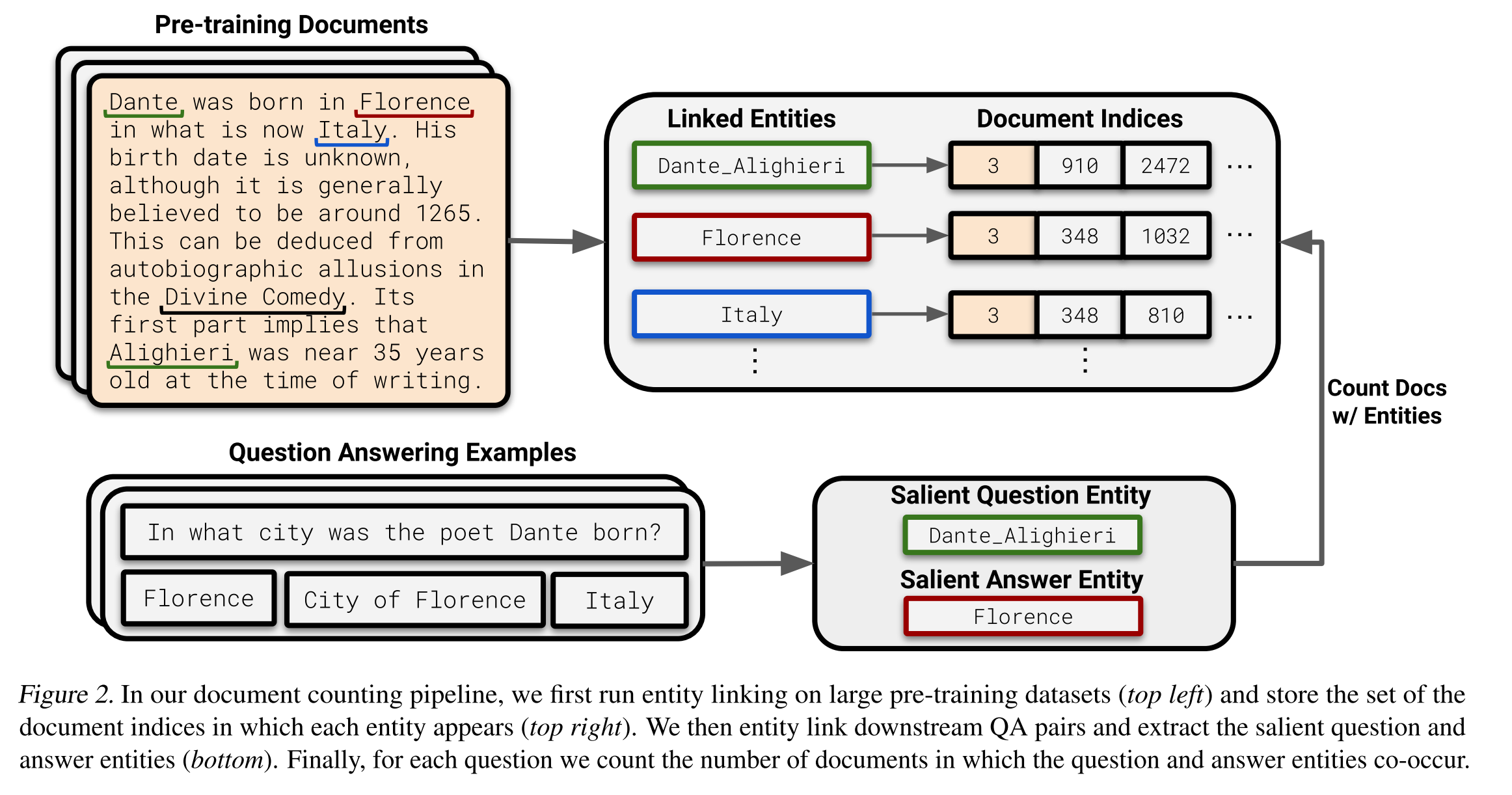
Paper reading "Large Language Models Struggle to Learn Long-Tail Knowledge" -- ICML2022
(1) Motivation: This paper investigates the relationships between the knowledge memorized in LLMs and the information in pre-training datasets scraped from the web. (2) Observations: this paper identified these relevant documents by entity linking pre-training datasets and counting documents that contain the same entities as a given question-answer pair and showed that a language model's ability to answer a fact-based question relates to how many documents associated with that question were seen during pre-training. They also demonstrated that retrieval-augmented methods could reduce the dependency of LLMs on relevant pre-training information, presenting a promising approach for capturing the long-tail. (3) Experiments: LLMs are GPT-Neo, BLOOM, and GPT-3. Pre-training datasets are The Pile, ROOTS, C4, PenWebText, and Wikipedia. Test QA datasets are TriviaQA and Natural Questions.
2023.11.02
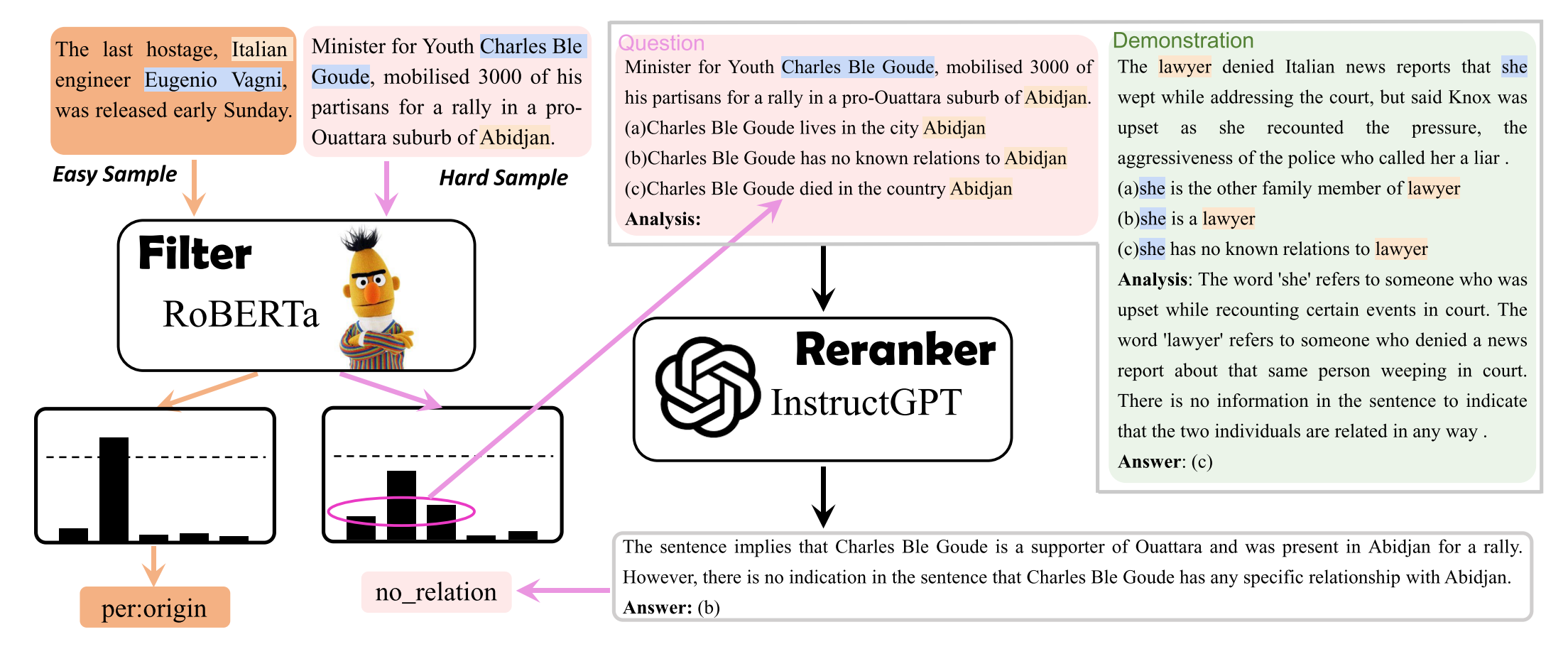
Paper reading "Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples!" -- EMNLP2023
(1) Motivation: this paper investigates the effectiveness of small pre-trained language models (SLMs) and large language models (LLMs) on few-shot information extraction and found that LLM could resolve hard examples better. (2) Methods: this paper have several conclusions. First, LLMs outperform SLMs only when the overall number of annotations is limited. Second, when we increase the number of samples (e.g., a few hundreds), SLMs outperform LLMs by a large margin. Third, calling LLMs API suffers from much higher inference latency and financial cost than finetuning SLMs locally. Last, LLMs are good at hard samples, though bad at easy samples. This paper proposed a novel adaptive filter-then-rerank framework to combine SLMs and LLMs considering both performance and cost in practice. The basic idea is that SLMs serve as a filter and LLMs as a reranker. In specific, SLMs make the first round of prediction, and if the sample is a hard one, this paper further passed the top-N candidate labels with highest prediction scores by SLMs to LLMs for reranking. (3) Experiments: With only 0.5%-13.2% of the samples being reranked, the adaptive filter-then-rerank system surpasses the previous state-of-the-art methods by an average 2.1% F1-score gain.
2023.10.25
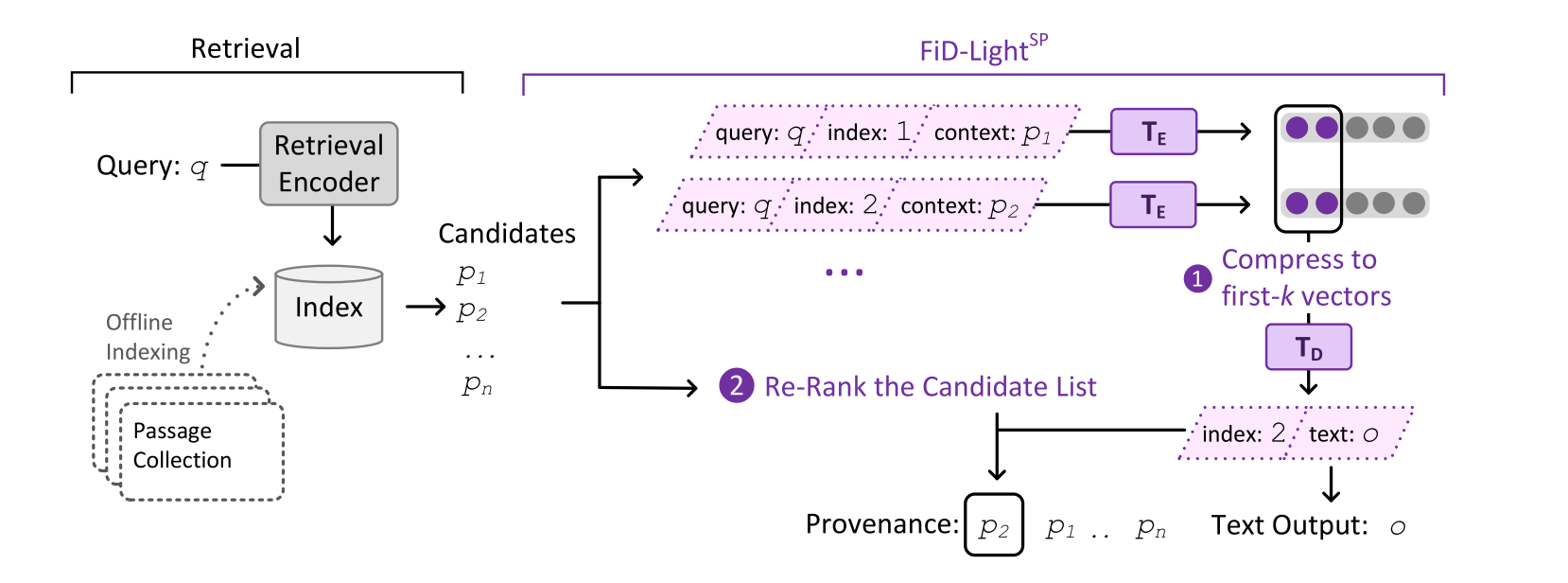
Paper reading "FiD-Light: Efficient and Effective Retrieval-Augmented Text Generation" -- SIGIR2023
(1) Motivation: Retrieval-augmented generation models offer many benefits over standalone language models: besides a textual answer to a given query they provide provenance items retrieved from an updateable knowledge base. However, they are also more complex systems and need to handle long inputs. (2) Methods: we introduce FiD-Light to strongly increase the efficiency of the state-of-the-art retrieval-augmented FiD model, while maintaining the same level of effectiveness. FiD-Light model constrains the information flow from the encoder (which encodes passages separately) to the decoder (using concatenated encoded representations). Furthermore, we adapt FiD-Light with re-ranking capabilities through textual source pointers, to improve the top-ranked provenance precision. (3) Experiments: Our experiments on a diverse set of seven knowledge intensive tasks (KILT) show FiD-Light consistently improves the Pareto frontier between query latency and effectiveness.
2023.10.18
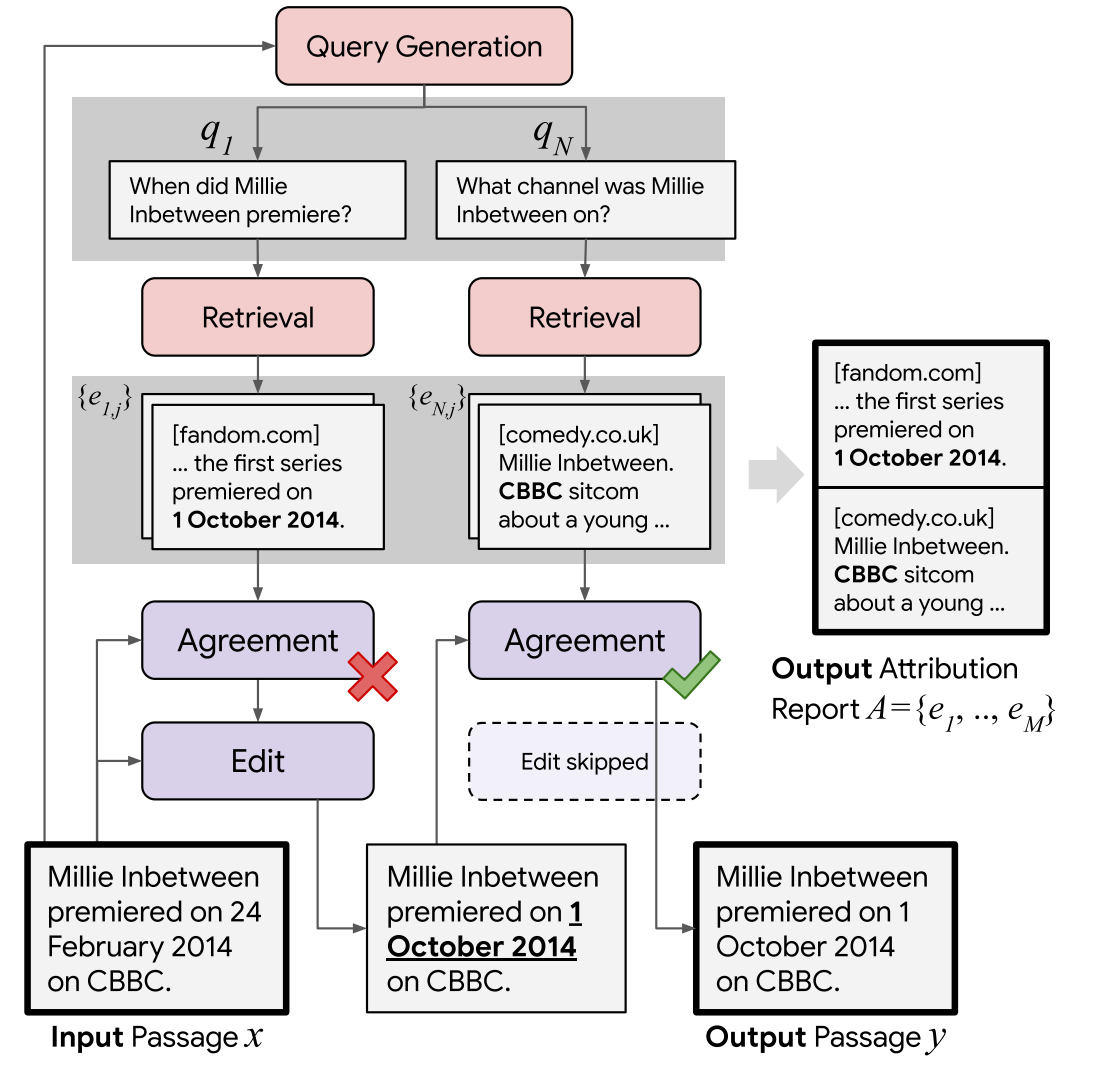
Paper reading "RARR: Researching and Revising What Language Models Say, Using Language Models" -- ACL2023
(1) Motivation: A user cannot easily determine whether their outputs are trustworthy or not, because most LMs do not have any built-in mechanism for attribution to external evidence. (2) Methods: To enable attribution while still preserving all the powerful advantages of recent generation models, we propose RARR (Retrofit Attribution using Research and Revision), a system that 1) automatically finds attribution for the output of any text generation model, and 2) post-edits the output to fix unsupported content while preserving the original output as much as possible. (3) Experiments: RARR significantly improves attribution while otherwise preserving the original input to a much greater degree than previously explored edit models.
2023.10.17
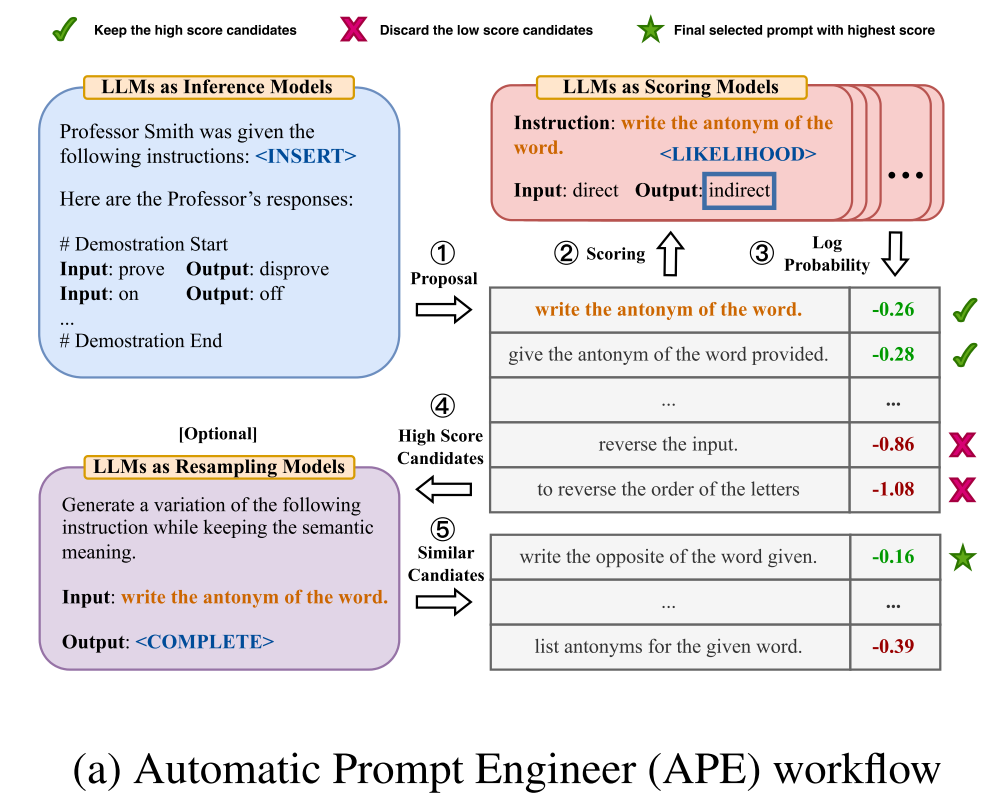
Paper reading "Large Language Models Are Human-Level Prompt Engineers" -- ICLR2023
(1) Motivation: Performance depends significantly on the quality of the prompt used to steer the model, and most effective prompts have been handcrafted by humans. (2) Methods: We propose Automatic Prompt Engineer(APE) for automatic instruction generation and selection. We treat the instruction as the “program,” optimized by searching over a pool of instruction candidates proposed by an LLM in order to maximize a chosen score function. To evaluate the quality of the selected instruction, we evaluate the zero-shot performance of another LLM following the selected instruction. (3) Experiments: APE-engineered prompts are able to improve few-shot learning performance, find better zero-shot chain-of- thought prompts, as well as steer models toward truthfulness and/or informativeness.
2023.10.16
Combine images online.
Combine images online.
2023.10.16
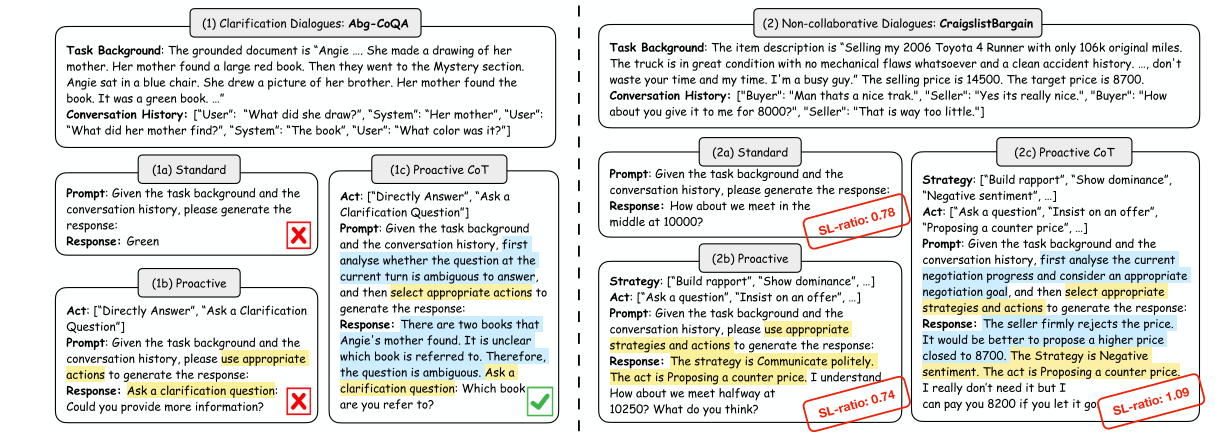
Ppaer reading "Prompting and Evaluating Large Language Models for Proactive Dialogues: Clarification, Target-guided, and Non-collaboration" - EMNLP2023 Findings
This paper investigates the LLMs-based conversational agent's proactivity, specifically focusing on three perspectives: clarification, target-guided, and non-collaborative dialogues. They proposed the proactive chain of thought prompting scheme, which analyzes the next action to take by performing dynamic reasoning and planning for reaching the conversational goal. The experiments are conducted from the above-mentioned three perspectives and they compared the performance of standard prompting, proactive prompting, and the proposed proactive chain-of-thought prompting schemes. This paper inspired me to think about an idea that gives LLMs alternative actions. In each step, the LLM could select an action and respond accordingly.
2023.10.11

Lecture Notes: "Towards Generative Search and Recommendation".
Introduce the use of LLMs for information seeking and the research directions in LLMs.
2023.10.10
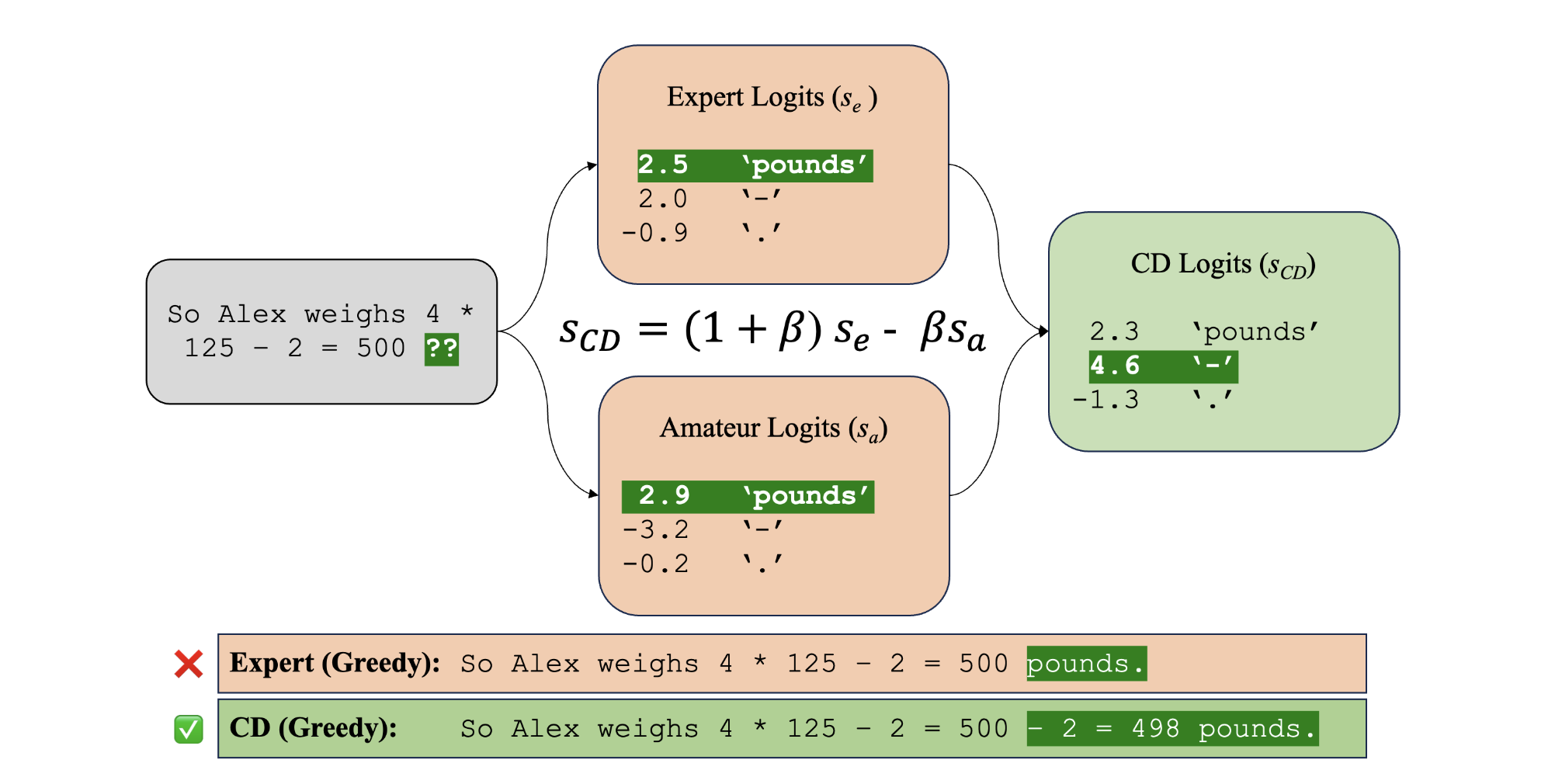
Rough reading "Contrastive Decoding Improves Reasoning in Large Language Models - arxiv2023".
This paper demonstrates that the existing contrastive decoding method could achieve large out-of-the-box improvements over greedy decoding on many reasoning tasks. Contrastive Decoding (CD) searches for strings that maximize a weighted difference in likelihood between a stronger expert and a weaker amateur model, and was shown by Li et al. to outperform existing methods for open-ended text generation. It achieves this by avoiding undesirable modes of the expert model’s distributions. They show that Contrastive Decoding outperforms greedy decoding on reasoning problems. Contrastive Decoding leads LLaMA-65B to outperform LLaMA 2, GPT-3.5 and PaLM 2-L on the HellaSwag commonsense reasoning benchmark, and to outperform LLaMA 2, GPT-3.5 and PaLM-540B on the GSM8K math word reasoning benchmark.
2023.09.20
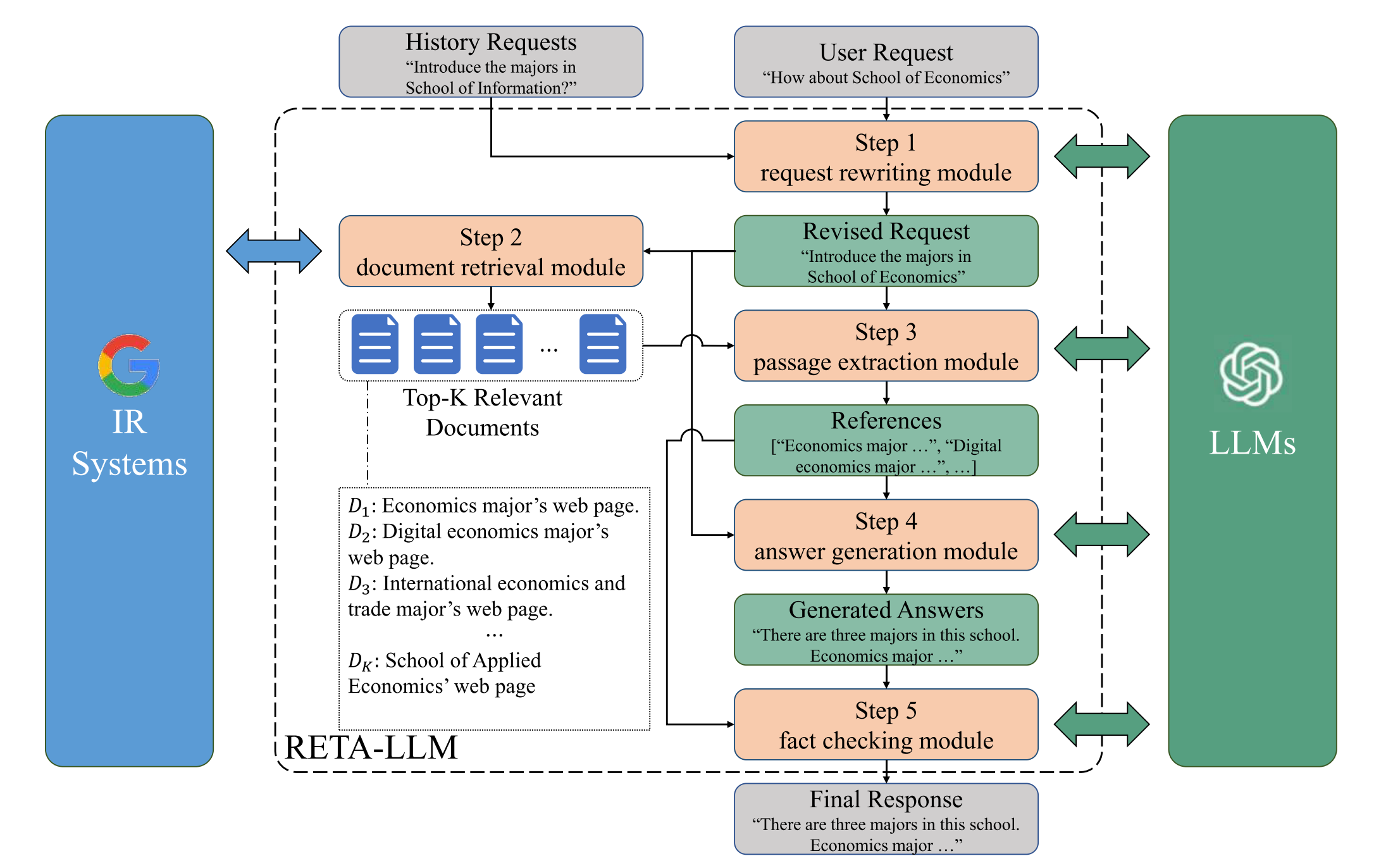
Paper reading "RETA-LLM: A Retrieval-Augmented Large Language Model Toolkit - arxiv2023".
This paper proposed a RETA-LLM, which contains three modules: (1) a request rewriting module ; (2) a passage extraction module ; (3) a fact checking module. RETA-LLM is part of YuLan, a open source LLM initiative proposed by Gaoling School of Ar- tificial Intelligence, Renmin University of China.
2023.09.20
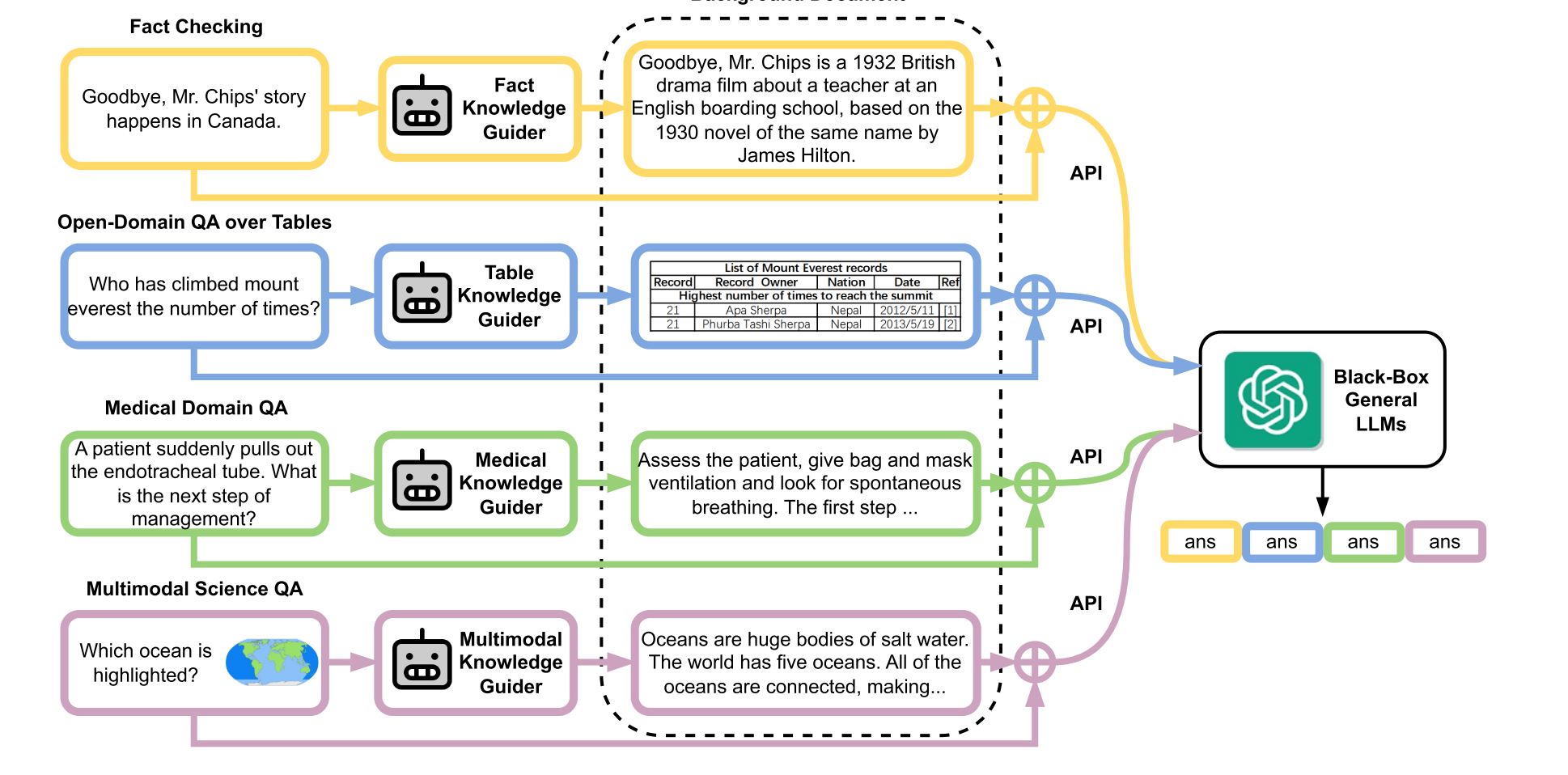
Paper reading "Augmented Large Language Models with Parametric Knowledge Guiding - arxiv2023".
Following the paper "GENERATE RATHER THAN RETRIEVE: LARGE LANGUAGE MODELS ARE STRONG CONTEXT GENERATORS - ICLR2023", this paper proposed a novel Parametric Knowledge Guiding framework (generate-then-read). This method used Llama-7B as a white box language model, which first generates relevant knowledge according to prompts. Then the generated knowledge is adapted to fine-tune the Llama-7B (Instruct tuning). Finally, the fine-tuned Llama-7B (white box) is equipped with GPT-3.5 (black box) to solve different downstream tasks. I think this method is effective, but it feels a bit like "killing a chicken without using a cow knife".
2023.09.18
Seaborn: statistical data visualization
Mark a good drawing tool.
2023.09.17
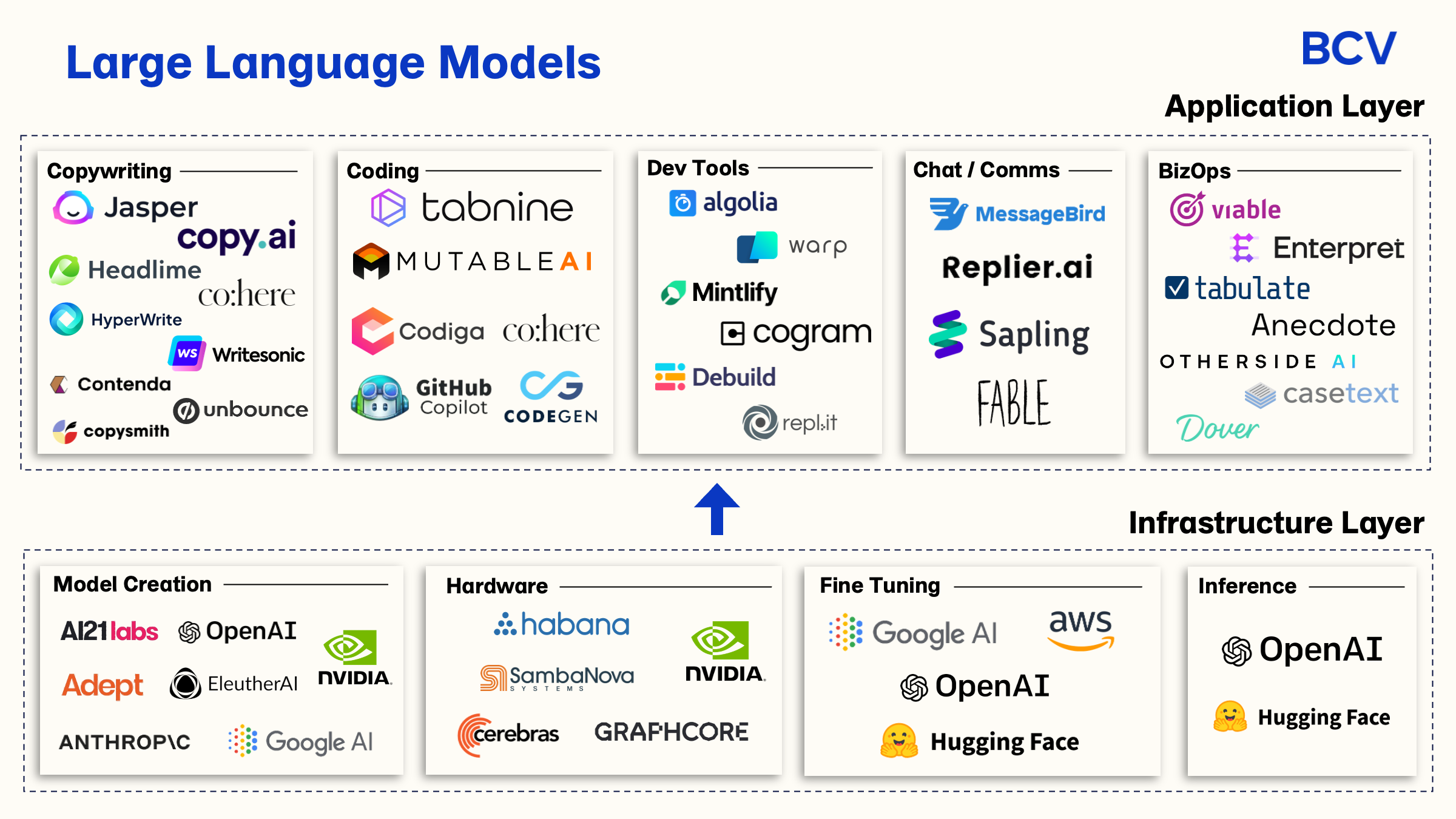
A paper list about Large Language Models
Record a paper list for LLMs.
2023.09.17
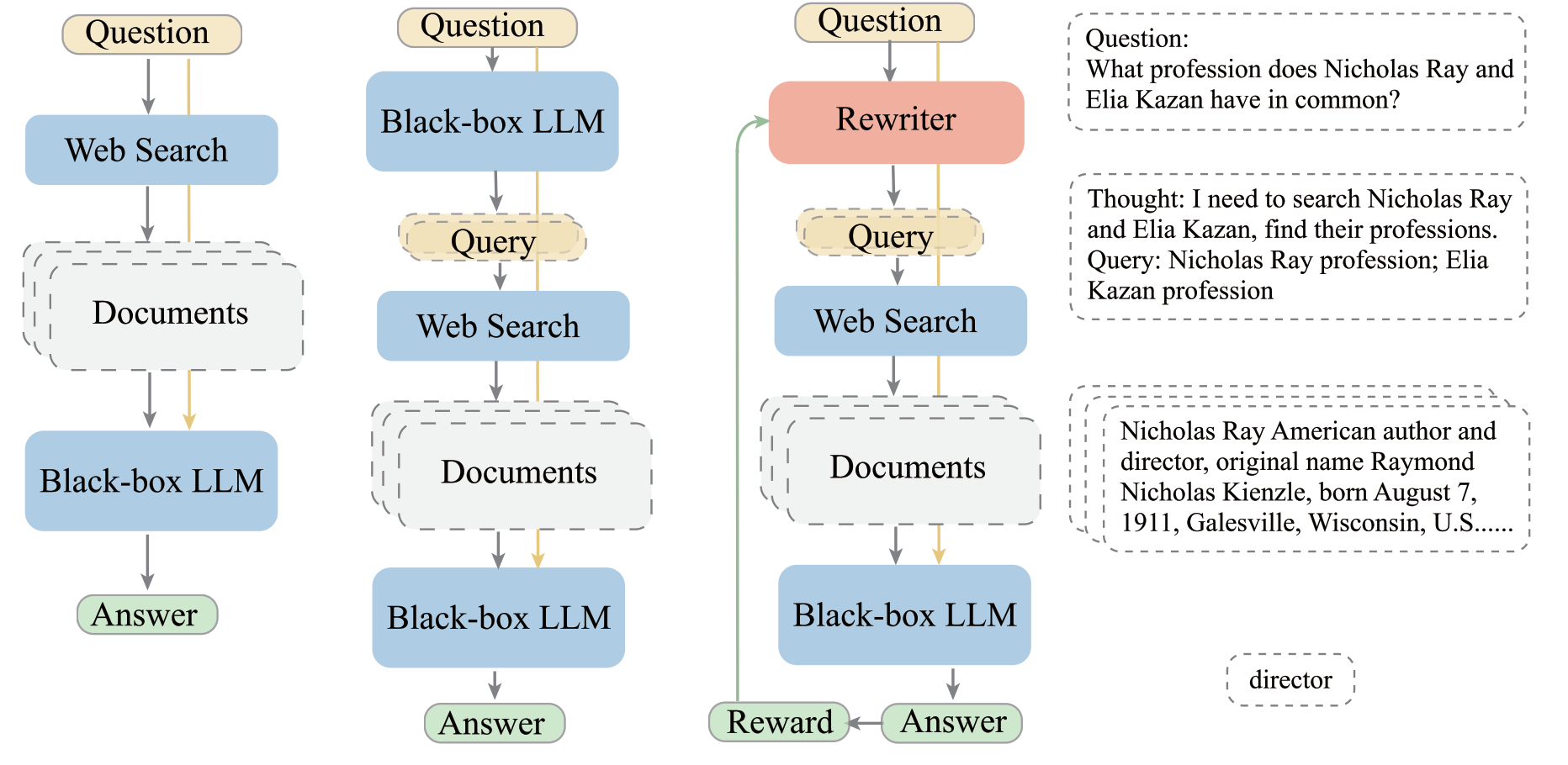
Rough Reading "Query Rewriting for Retrieval-Augmented Large Language Models"
This paper proposed a rewrite-retrieve-read pipeline to improve the performance of LLM. Different from existing methods of adapting the retriever or simulating the reader, this paper proposed to rewrite the query with a small language model. Specifically, they first prompt the LLM to generate some pseudo data to train the warm-up rewriter. Then the PPO is used to optimize the rewriter. The experiments seem to be incomplete, but this paper provides a novel idea and perspective for retrieval-augmented LLMs. The PPO should be further figured out.
2023.09.15

Rough Reading "Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy"
Existing retrieval-augmented LLMs adopt one-time retrieval, which (1) fails to process all the knowledge as a whole during the generation process; (2) invokes retrieval multiple times and may frequently change the prompts by updating newly retrieved knowledge. This paper proposed an iterative retrieval-generation synergy, which alternates between a retrieval-augmented generation process and a generation-augmented retrieval process. A knowledge distillation from a re-ranker is used to help the retriever better address the semantic gaps between a question and its supporting knowledge. Experiments are conducted on four QA datasets. An ACC* metric also be adopted to evaluate the model in a more robust way. This paradigm is similar to the idea in our paper "self Question-answering ...".
2023.09.14
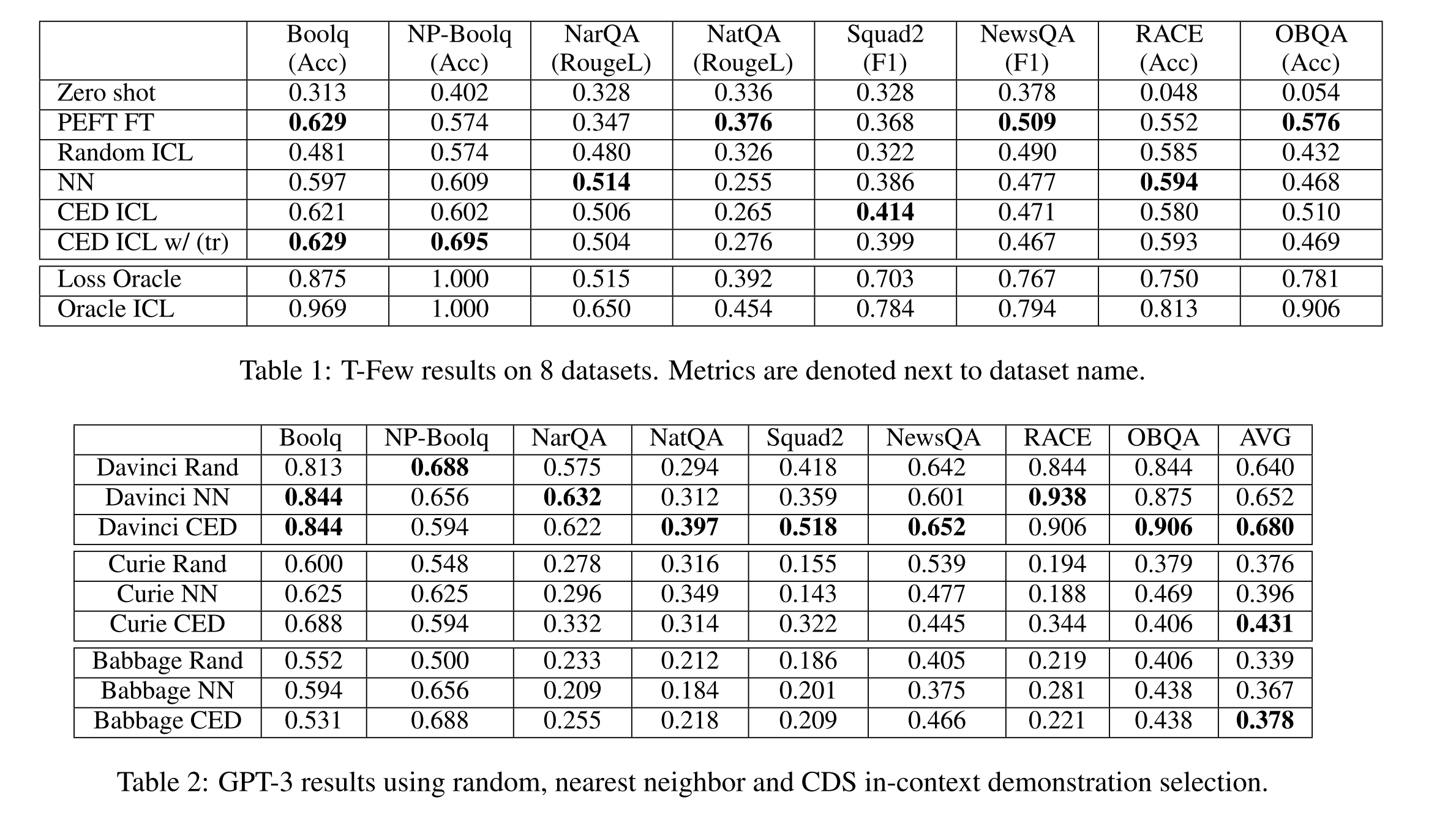
Rough Reading "In-Context Demonstration Selection with Cross Entropy Difference"
This paper proposed to select in-context demonstrations based on cross-entropy difference, which is based on the idea of meta-gradient. This paper also provides theoretical guidance for why selecting demonstrations based on their gradient alignment with test examples is an effective heuristic. This paper seems to be an unfinished paper, but it provides a good idea and a new perspective on demonstration selection.
2023.09.12

Rough Reading "RaLLe: A Framework for Developing and Evaluating Retrieval-Augmented Large Language Models - Arxiv2023"
This paper proposed a development and evaluation framework for retrieval-augmented LLMs (R-LLMs), namely RALLE. Current libraries for building R-LLMs provide high-level abstractions without sufficient transparency for evaluating and optimizing prompts within specific inference processes such as retrieval and generation. With RALLE, developers can easily develop and evaluate R-LLMs, improving hand-crafted prompts, assessing individual inference processes, and objectively measuring overall system performance quantitatively. This paper provides a graphical interface for users to select, combine, and test various retrievers and LLMs.
2023.09.12
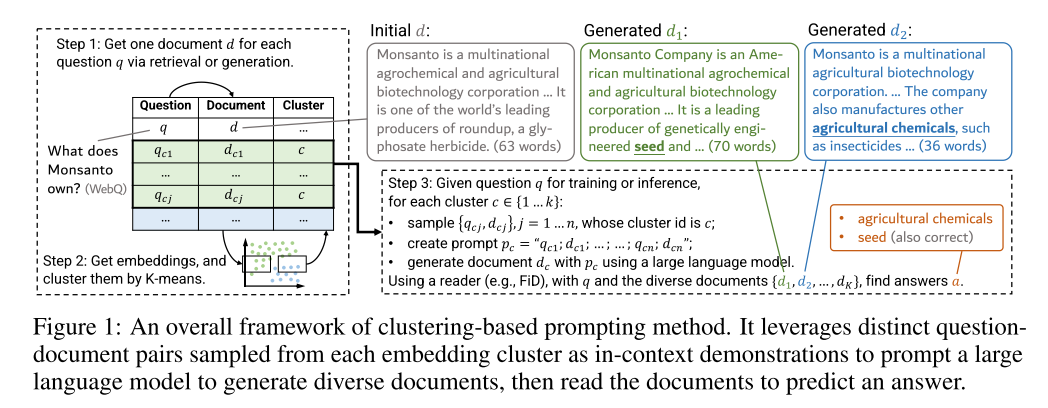
Rough Reading "GENERATE RATHER THAN RETRIEVE: LARGE LANGUAGE MODELS ARE STRONG CONTEXT GENERATORS - ICLR2023"
Previous retrieval-augmented methods employ a retrieve-then-read pipeline, which suffers from three drawbacks:
(1) candidate documents for retrieval are chunked and fixed, containing noisy information;
(2) interactions between the input and documents are shallow;
(3) encoding a large number of candidates is time-consuming.
This paper proposed a generate-then-read method, which first prompts LLMs to generate contextual documents and then uses them to obtain the answer.
A clustering-based prompting approach to generate multiple diverse contextual documents is proposed to increase the likelihood of covering the answers.
Experiments on three knowledge-intensive NLP tasks prove the superiority of the proposed method compared to previous augmented methods.
2023.09.08
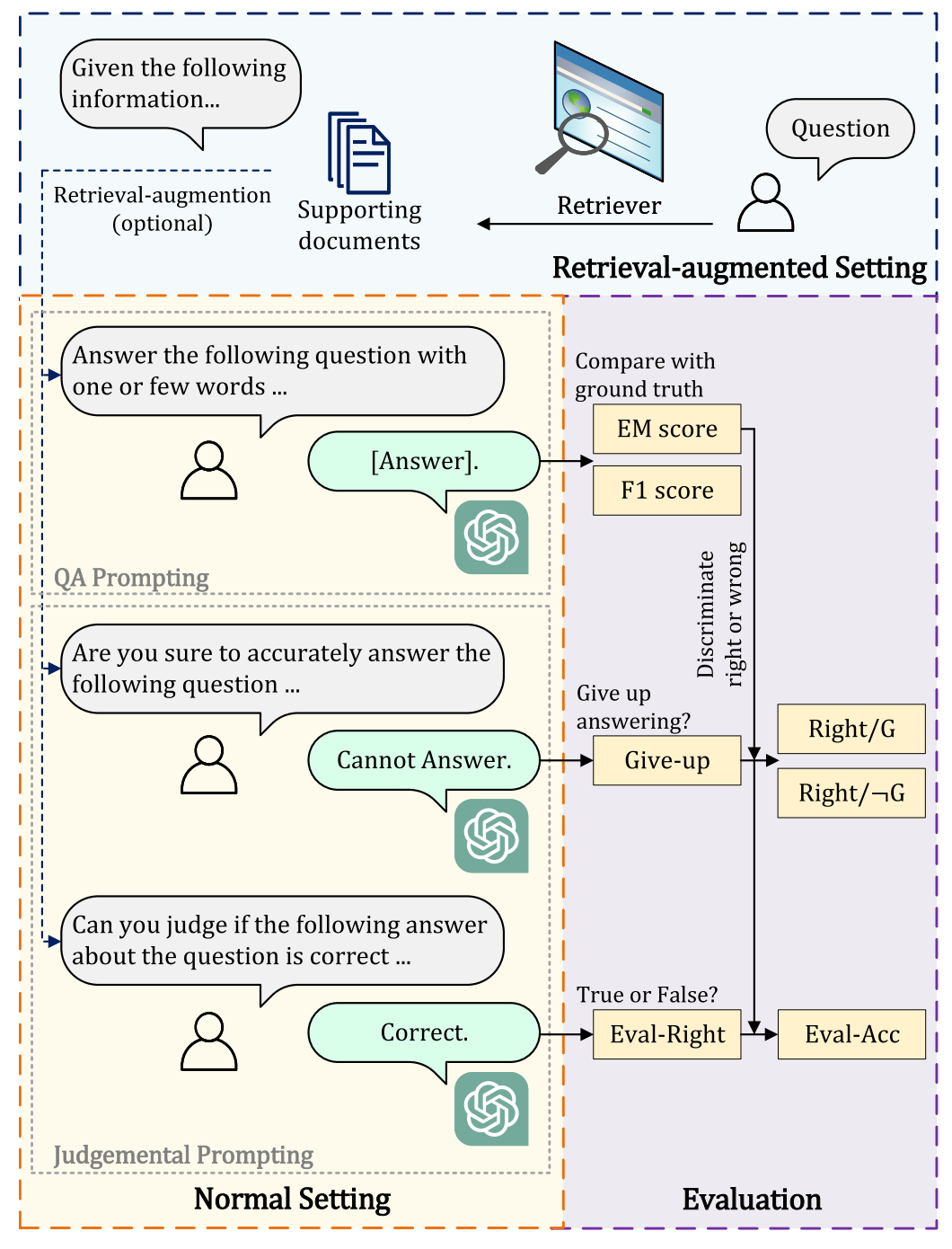
Rough Reading "Investigating the Factual Knowledge Boundary of Large Language Models with Retrieval Augmentation"
This paper investigates the knowledge boundary of LMMs and how retrieval augmentation affects LLMs on open-domain tasks.
This study answere three questions:
1. To what extent can LLMs perceive their factual knowledge boundaries?
LLMs perceive their factual knowledge bound- ary inaccurately and have a tendency to be over- confident. In
2. What effect does re- trieval augmentation have on LLMs?
(1) LLMs cannot sufficiently utilize the knowledge they possess, while retrieval augmentation can serve as a valuable knowledge supplement for LLMs.
(2) Retrieval augmentation improves LLM’s ability to perceive their factual knowledge boundaries.
(3) More supporting documents continuously improve the performance of retrieval-augmented LLMs.
(4) Retrieval augmentation can change the preference of LLMs towards different query categories.
3. How do supporting documents with different characteristics
(1) LLMs demonstrate enhanced capabilities in QA abilities and perception of knowledge boundaries when provided with higher quality supporting documents.
(2) LLMs tend to rely on the given supporting documents to answer.
(3) The level of confidence and reliance on supporting documents of LLMs is determined by the relevance between the question and the supporting documents.
The experiments are conducted by the usage of LLMs APIs.
2023.09.07
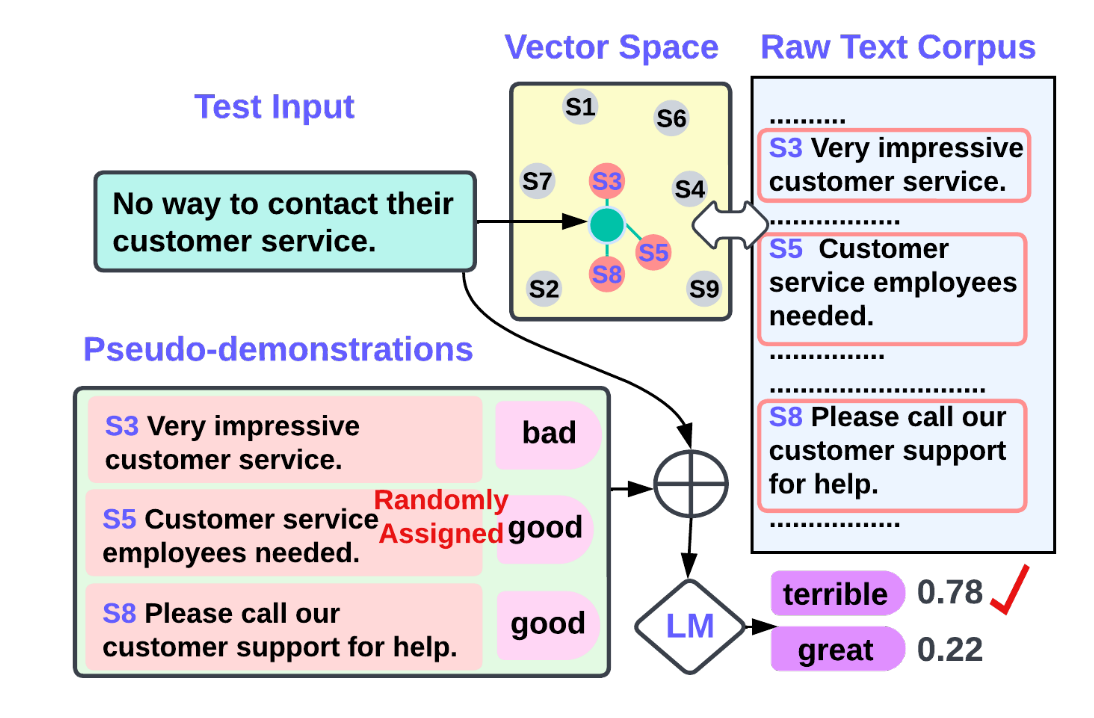
Rough Reading "Z-ICL : Zero-Shot In-Context Learning with Pseudo-Demonstrations"
This paper introduce Z-ICL: Zero-shot In-Context Learning through creating pseudo-demonstrations, which achieves results on par with in-context learning from gold demonstrations. This paper first explain the Copying Effect Hypothesis in ICL, which means that ICL tends to copy the input-label distribution of similar demonstration. To alleviate the copy effect, this paper proposed to retrieve physical neighbors from a raw corpus. Then synonym labels are randomly assigned to the neighbors. Finally, they concatenate the pseudo-demonstrations with the initial input x and inference the results. The authors think future work can explore better construct- ing the pseudo-demonstrations.
2023.09.06
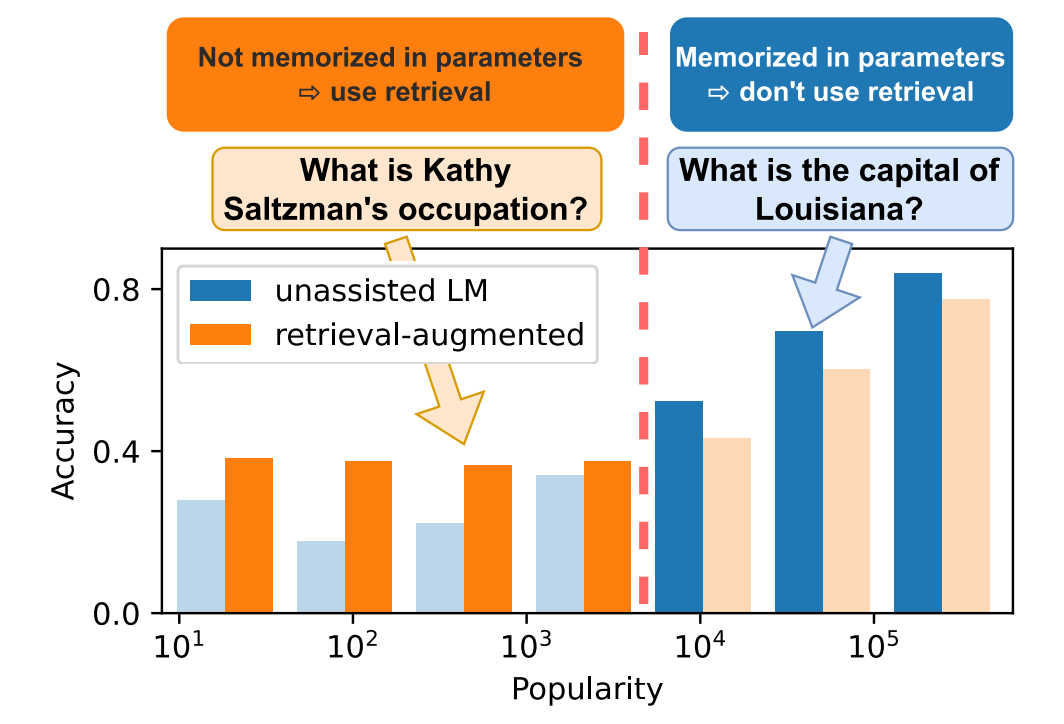
Rough Reading "When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories"
This paper investigates that large language models store popular factual knowledge in parametric memorization while struggles with less popular knowledge (long tail). The proposed adaptive retriever uses retrieval when the popularity of input is lower than a threshold. The analysis results are as follows: 1. Memorization Depends on Popularity and Relationship Type. (1) Subject entity popularity predicts memorization: more popular subject entity indicates better the memorization. (2) Relationship types affects memorization: some relationships are easier to be memorized. (3) Scaling may not help with tail knowledge. (4) Relationship type results breakdown. 2. Non-parametric Memory Complements Parametric Memory. (1) Retrieval largely improves performance. (2) Non-parametric memorizations are effective for less popular facts. (3) Parametric memorizations may mislead LMs. 3. Adaptive Retrieval: Using Retrieval Only Where It Helps. Adaptive Retrieval improves performance and reduces the inference time cost. The threshold shift with LM scale.
2023.09.06
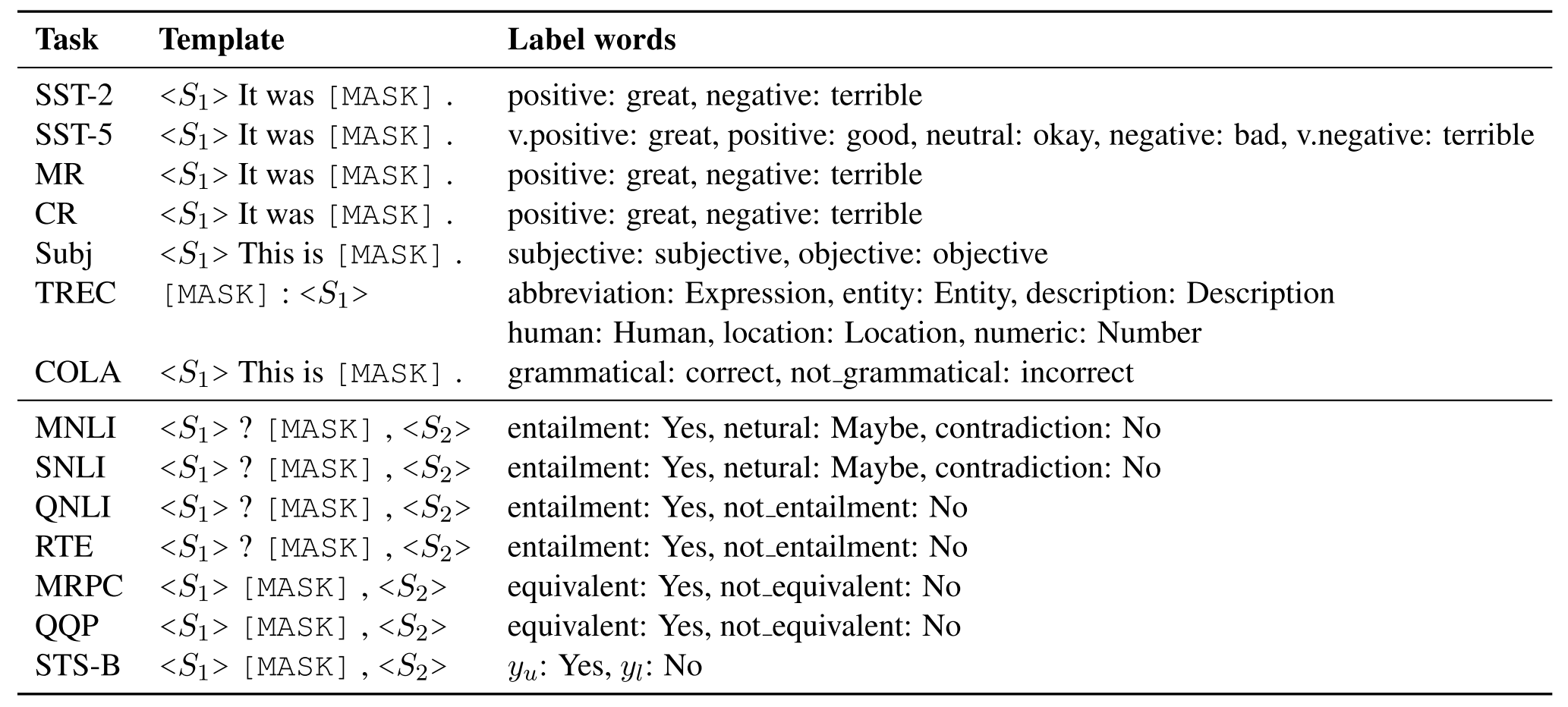
Paper Reading "Making pre-trained language models better few-shot learners"
Since the ICL (GPT-3) is not parametric efficient, this paper aims to study few-shot learning in a more practical scenario, where they use smaller language models for which fine-tuning is computationally efficient. On the one hand, they proposed an automating prompt generation method, which could automatically map a class with a word and generate a template to organize an examples pair. On the other hand, they designed a dynamic demonstrations selection method to selecte demonstrations for each class and improve the performance of downstream tasks. Experiments prove the effectiveness of different generated templates and compare them with manully templates. Please refer to the specific paper for more experimental details.
2023.09.06

Rough Reading "Understanding In-Context Learning via Supportive Pretraining Data"
This paper investigates how the pretraining data helps in-context learning. The authors adopt an iterative, gradient-based method to find a small subset of the pretraining data that supports ICL. They find that continued pretraining on the selected subset improves the ICL performance compared to a random subset. They have 3 interesting observations: (1) the supportive pretraining data do not have an inevitable domain relevance with the downstream task; (2) The supportive pretraining data have a higher mass of rarely occurring, long-tail tokens; (3) The supportive pretraining data are challenging examples where the information gained from long-range context is below average. The metrics used in this paper to evaluate the relationships between pretraining data and the input text are very reasonable and impressive. This paper uses the similarity between gradients to find supportive pretraining data, which provides a guidance for the direction the model parameters should be updated towards to be better at ICL.
2023.09.05

行列式点过程(Determinantal Point Process, DPP)
In mathematics, a determinantal point process is a stochastic point process, the probability distribution of which is characterized as a determinant of some function. -- Wikipedia.
2023.09.04
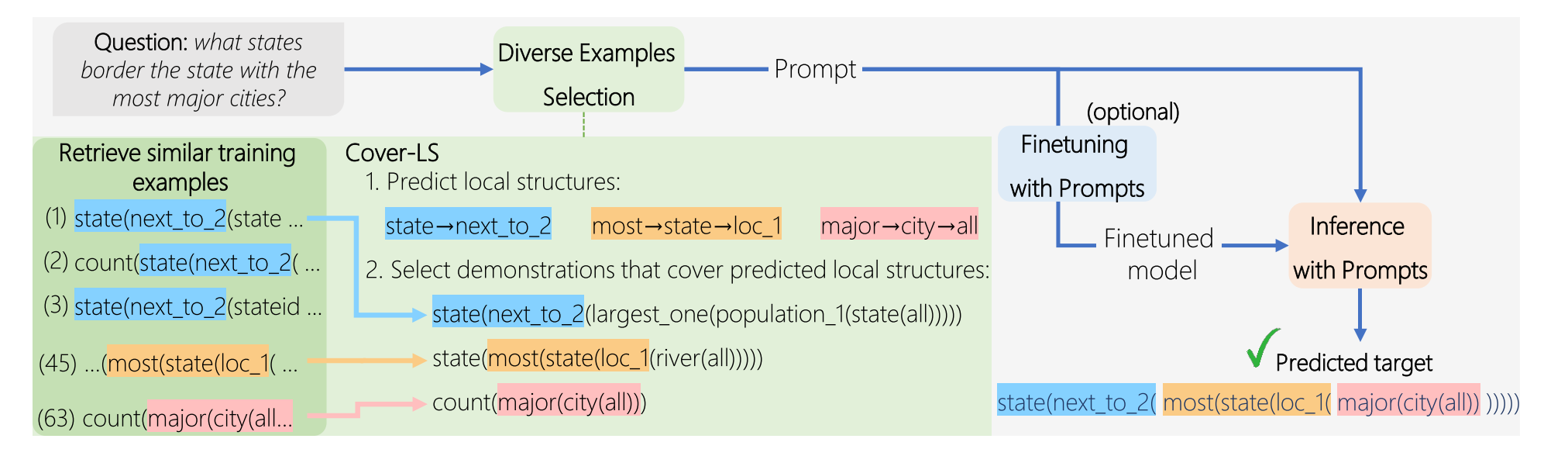
Paper Reading "Diverse Demonstrations Improve In-context Compositional Generalization" -- ACL2023
This paper proposed a new demonstration selection method for in-context learning in the setup of compositional generalization. Considering that there is no example that is similar enough to the input, the proposed method takes into account both the similarity and diversity among different demonstrations. Specifically, they proposed two approaches for increasing diversity: (a) a cover-based approach; and (b) an approach that selects a subset of examples that are most dissimilar with each other (using DPP). Experiments across three compositional generalization semantic parsing datasets show that combining diverse demonstrations with in-context learning substantially improves performance in the pure in-context learning setup and when combined with fine-tuning.
2023.09.04
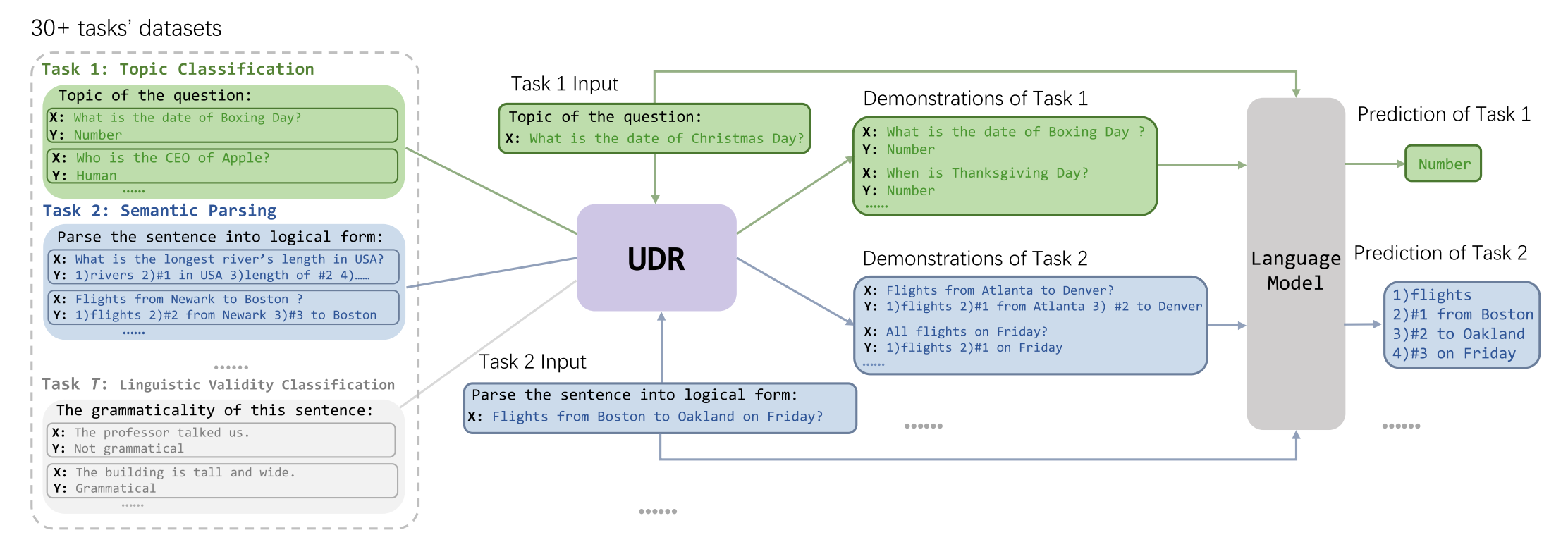
Paper Reading "Unified Demonstration Retriever for In-Context Learning" -- ACL2023 Oral
This paper proposed to retrieve demonstrations from the training set for ICL, which could jointly train several NLP tasks and yeild a unified model. This paper convert the demonstration selection as a list-wise ranking problem and design an interative candidates selection method. Experiments on 30+ NLP tasks proved the effectiveness of the proposed framework. The experimental amount is impressive.
2023.09.02
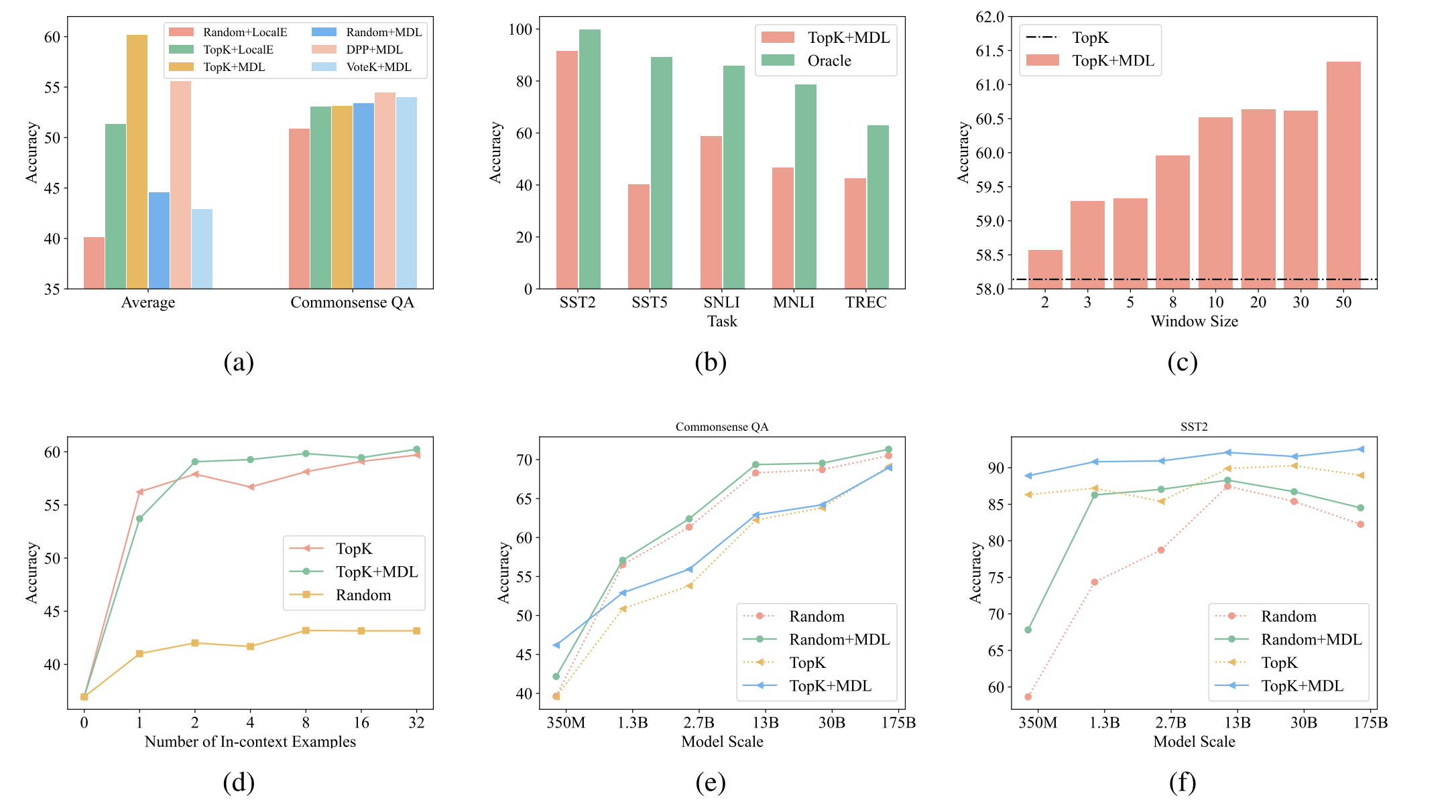
Paper Reading "Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering" -- ACL2023 Oral
This paper proposed a new task, namely self-adaptive in-context learning, which seeks to construct good-performing in-context example organization for each testing sample individually. Existing methods could be sub-optimal because they are in corpus-level. This paper proposed an instance-level method containing selection and ranking to find better examples organizations for ICL.
2023.09.01
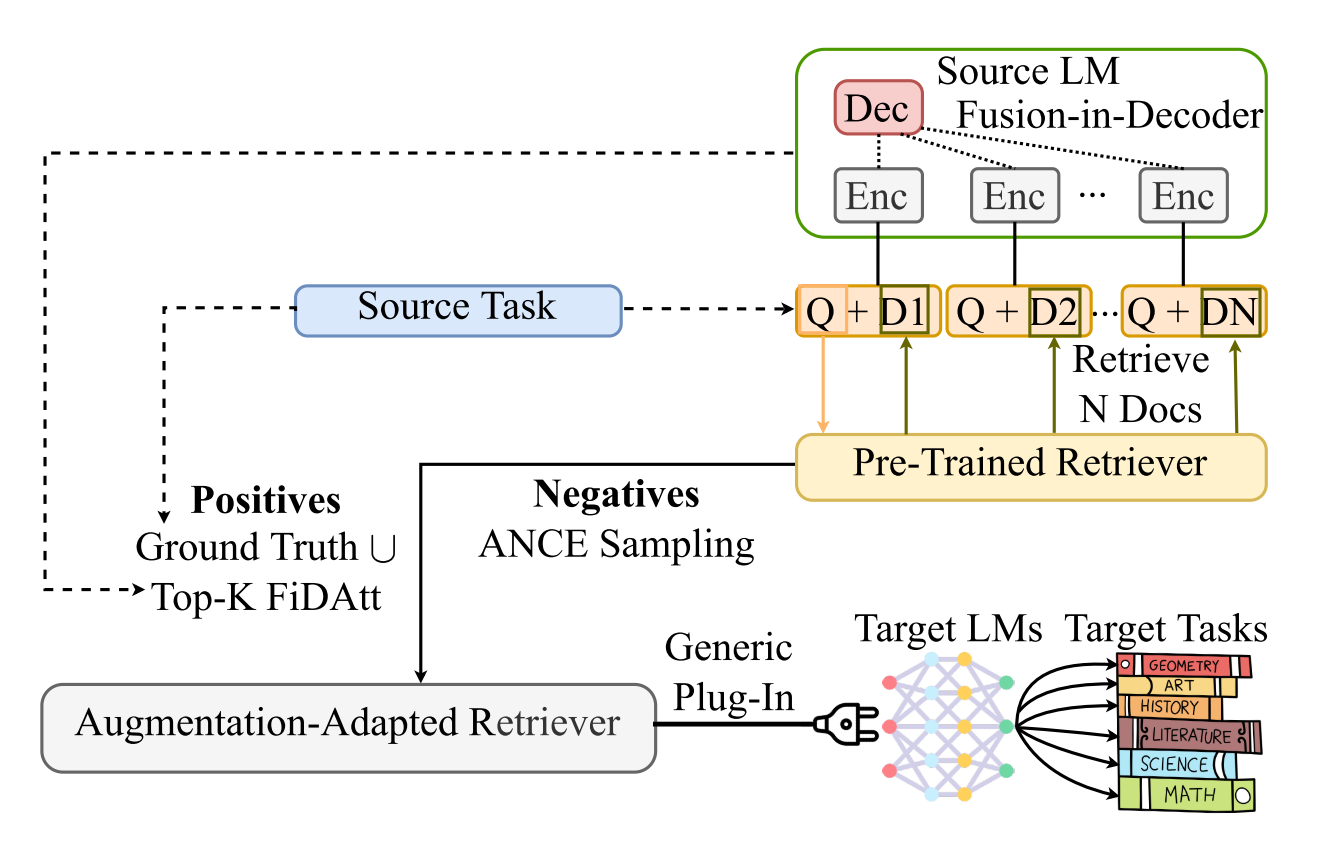
Paper Reading "Augmentation-Adapted Retriever Improves Generalization of Language Models as Generic Plug-In" -- ACL2023 Oral
This paper proposed a simple yet effective method, namely augmentation-adapted retriever (AAR), which pre-trained a retriever based on a source LM and plugged the retriever into a target unseen LM. The experiments and analysis are insightful.
2023.08.22

Sweety and Tiny.
Sweet Baby is a black schnauzer, born in October 2018. Tiny is a brown Teddy dog, born in April 2019.
2023.09.19

My first blog.
Welcome to my first blog. I share my daily life and record my research process.
2022.11.18

Coming soon.
There is nothing
2022.--.--