1. Calibration 校准
Calibration是指模型对事件的输出概率和事件实际发生的概率的一致性,一致性越高越好。在机器学习场景下,尤其是二分类任务中,模型输出的概率往往被解释为样本属于正类的概率。如果一个模型是完美校准的,那么当模型输出事件概率为
Calibration所衡量的这种一致性对于许多应用场景都是重要的,特别是在需要对模型的概率输出进行可靠解释和决策的情况下。当一个模型是校准的,且输出一个置信度(conditional probability)较低的答案时,可以对该结果进行人工修正等操作。
2. Expected Calibration Error (ECE) 期望校准误差
期望校准误差是一种评估校准概率的指标,它通过将样本划分成多个概率区间(或称为箱子),然后计算每个区间内的模型概率与实际发生频率之间的差异来衡量模型的校准性能。具体计算方法如下:
其中,
ECE 的值越低,表示模型的概率输出与实际发生的频率越一致,即模型的概率输出更加校准。
举个例子,在文章“Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback”中有一个使用ECE衡量大模型calibration的实验,如下图:
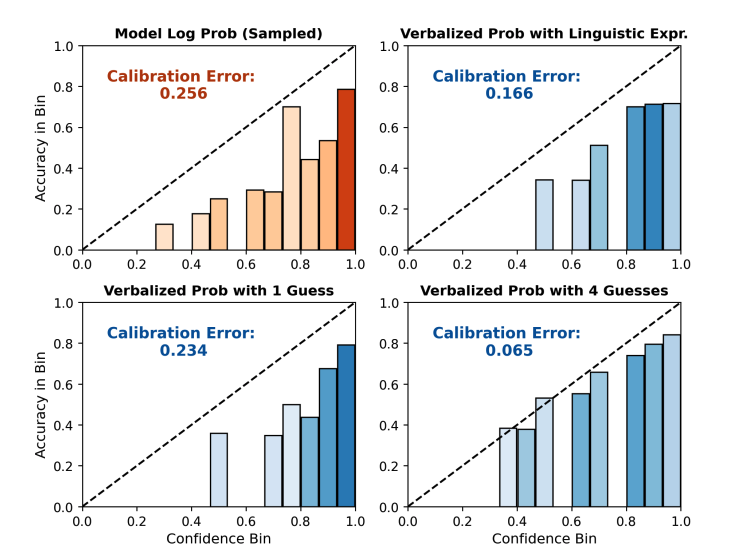
横轴表示的是划分的桶🪣,纵轴是在每个桶上的accuracy,虚线是一个完美校准的边界,柱形图的表现越靠近虚线,表示模型校准越好。观察四张图可以看出左上角的ECE最高,校准最差;右下角的ECE最小,校准最好。
这里值得一提的是,我理解的ECE其实是衡量一个模型对自己的判断的自信程度,或者说这个模型有没有自知之明,并不能反映一个模型在下游任务上的性能的好坏。并且,只有在模型performance比较好的时候评价ECE才有意义,不然一个模型本身就在胡说八道(ACC低),那么它知道自己在胡说八道(ECE低)也没啥意义。下面是一个更具体的解释:
在二元分类中,一个系统每次随机猜测,并且输出50%的置信度,拥有完美的期望校准误差(Expected Calibration Error,ECE)可能在理解上有些反直觉,但这可以通过理解ECE的定义和计算来解释。
ECE用于评估模型预测概率的校准性。校准性指的是模型预测的概率与实际观察到的事件发生概率之间的一致性。在二元分类场景中,校准性体现了预测概率对正类别的估计有多准确。
我们来逐步解释这个情景:
- 系统随机猜测: 如果系统是随机猜测,这意味着它平均而言每次都会有50%的正确率。
- 每次输出50%置信度: 当系统输出50%的置信度时,实际上是在表达它对哪个类别更有可能没有偏好或信息。这是关键点。
现在,考虑当你计算这个系统的ECE时会发生什么。ECE通过将整个概率范围划分为多个区间(桶),然后比较每个区间内的平均预测置信度与该区间内的实际准确性(正确预测的比例)之间的差异来计算的。
对于随机猜测系统,每个区间的平均预测置信度都将是50%。由于系统是随机猜测的,每个区间内的实际准确性也会接近50%。因此,预测置信度与实际准确性之间的绝对差异在每个区间内都非常小。
当将这些小的绝对差异在所有区间内求和并进行标准化时,你将得到一个非常小的ECE值。事实上,在你描述的情况下,ECE将接近零,表示根据ECE指标,这个系统的校准是完美的。
这并不意味着这个模型是好的或有用的;它只是说明了预测概率与实际准确性的一致性,在每次都随机猜测且输出50%置信度的情况下,这种一致性是微不足道的。 ECE指标在评估能够做出有根据的预测而非随机猜测的模型的校准性时更具有意义。
3. 大模型校准
最近不少研究都提到大模型的over-confidence问题,就是说大模型输出答案的conditional probability要比实际上的概率要高一些,当高到一定程度就导致了大模型幻觉的问题。用上面说的ECE来表达的话,就是校准太差,模型概率和实际概率差太多了。有研究表明[1] [2],大模型经过RLHF的方式训练之后,会加重over-confidence的问题,因为RLHF更加关注最大化用户偏好的内容的生成概率,而忽略了所有可能的生成的概率的平衡,当然这个我没有深入去看了。既然如此,RLHF-LLM都有这个校准很差的问题,有没有什么办法去缓解呢?文章“Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback”就做了大量的实验,发现设计prompts使得大模型通过回答问题对自己的预测结果输出更加准确的概率判断,这个概率要比大模型本身输出的conditional probability的校准效果更好。比如在大模型回答完一个问题后,我们编写prompt让大模型回答对这个回答的准确程度,具体来说可以回答一种概率表述,比如说可能、很可能、概率很大等等,也可以回答一个具体的
值得一提的是,这篇文章虽然没有给出太多的解释性的内容,但是它发现了上述的现象,并提了很多future work,容易给我们一些启发和对未来工作的思考。比如在文章结尾,作者认为将来应该更好地解释1. 为什么使用差不多的prompts对不同的大模型的校准的影响不一样?是什么因素影响的?数据还是训练方式?2. 虽然设计prompts能提升校准,但是提升的程度对prompt比较敏感,怎么去缓解这种敏感?3. 对QA问题,能否将校准良好的shot-form QA的优势扩展到long-form QA?4. 模型的校准收到domain的影响有多大? 后两个问题我其实没有太深入的思考。
一方面是这篇文章是个短文,所以只总结了一些发现,另一方面呢,这个文章最后提出的每一个问题都不是一个简单的可以解释的问题,可能我们一下子都说不出来到底为什么。就好比大家都会致力于解决如何找好的example提升ICL的性能,但是真的提升了以后再去看那个使得性能提升的examples我们反而很难看出它到底跟别的example有什么不同。
感觉自己以后应该多看一些类似的工作,能够引发我的思考和遐想,也是对热点以及未来工作的一些预测吧。
[1] Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec, Liane Lovitt, Kamal Ndousse, Catherine Olsson, Sam Ringer, Dario Amodei, Tom Brown, Jack Clark, Nicholas Joseph, Ben Mann, Sam McCandlish, Chris Olah, and Jared Kaplan. 2022. Language models (mostly) know what they know. Arxiv arxiv:2207.05221.
[2] OpenAI. 2023. Gpt-4 technical report